[论文笔记] DINOv2
信息
Title: DINOv2: Learning Robust Visual Features without Supervision
Author: Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, Piotr Bojanowski
Publish: TMLR
Year: 2023
Code: https://github.com/facebookresearch/dinov2?tab=readme-ov-file
Keyword:
背景
生成视觉基础模型相对有效的是文字引导的预训练
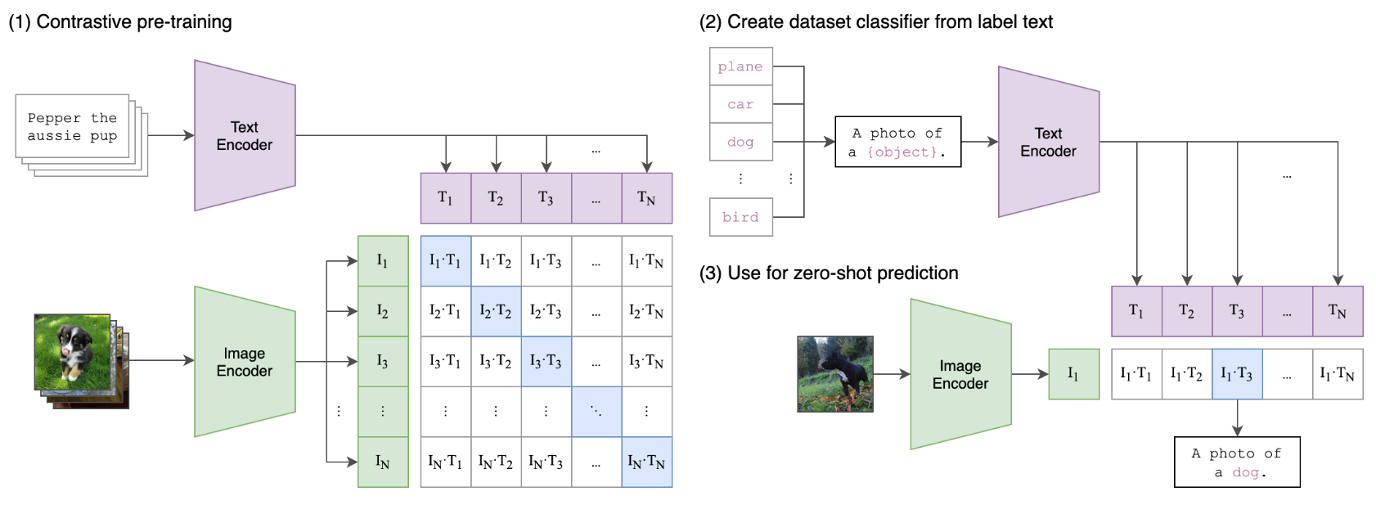
然而:
- 由于文字只能大致给图像做标注,会导致复杂的像素信息不能表露•(缺乏像素理解能力)
- 同时需要图像-文本对(需要模态对齐获取高质量数据)
MAE需要下游任务微调
现有的自监督的缺陷:
- 在相对较小的数据集(ImageNet-1k)上训练,无法大规模拓展
- 大规模预训练使用uncurated datasets(没有仔细挑选,自动爬取,系统标注,质量不高)
作者对自监督的分类:
- 图像内自我的自监督:重上色,预测变化,path重排序。。。MAE
- 图像间的对比:可以给予物体级和聚类
由此,对比级可以较好的冻结特征,但难以scale
scaling:
scaling不仅仅针对模型,还要针对数据
- 作者认为现有的模型scale受限于数据质量,需要在微调之后测试
数据清洗:
- 许多方法会使用元数据或者预训练的视觉编码器来去除不好的数据
贡献:
- 在仔细挑选的数据上的大规模自监督预训练
- 改进在大规模预训练过程上的稳定和加速技术
- 使用一个聚类技术建立了自动化的分离和平衡数据的过程,最终收集到142M图像
数据预处理
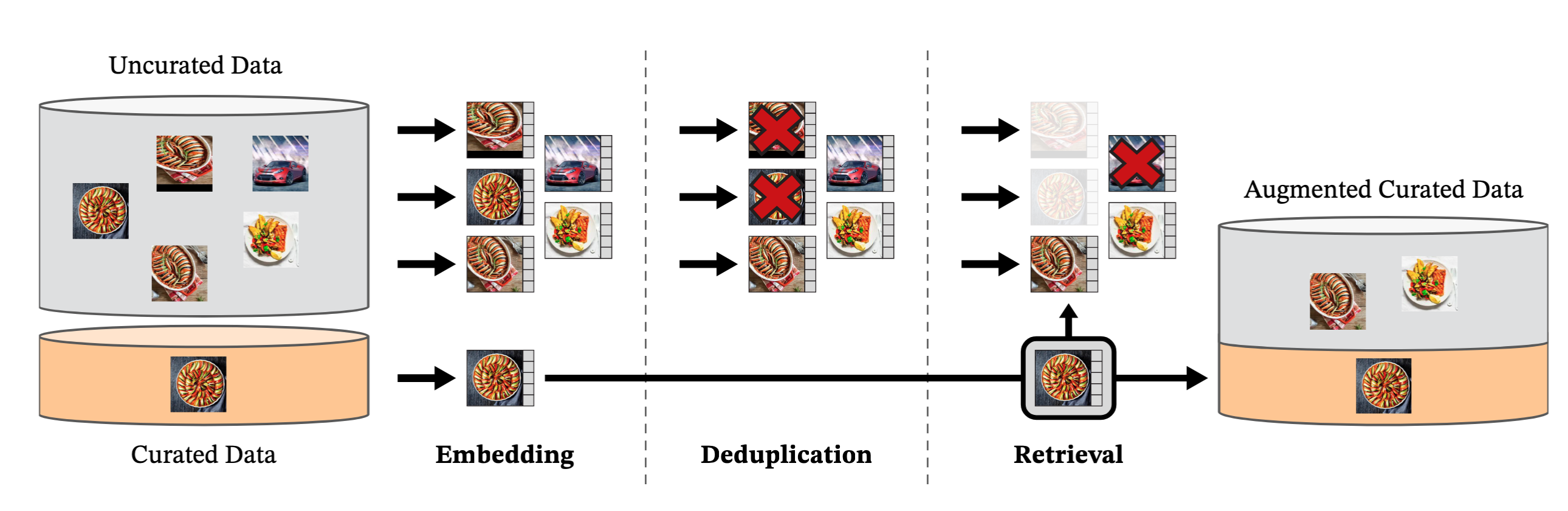
数据源
标记好的数据源为:
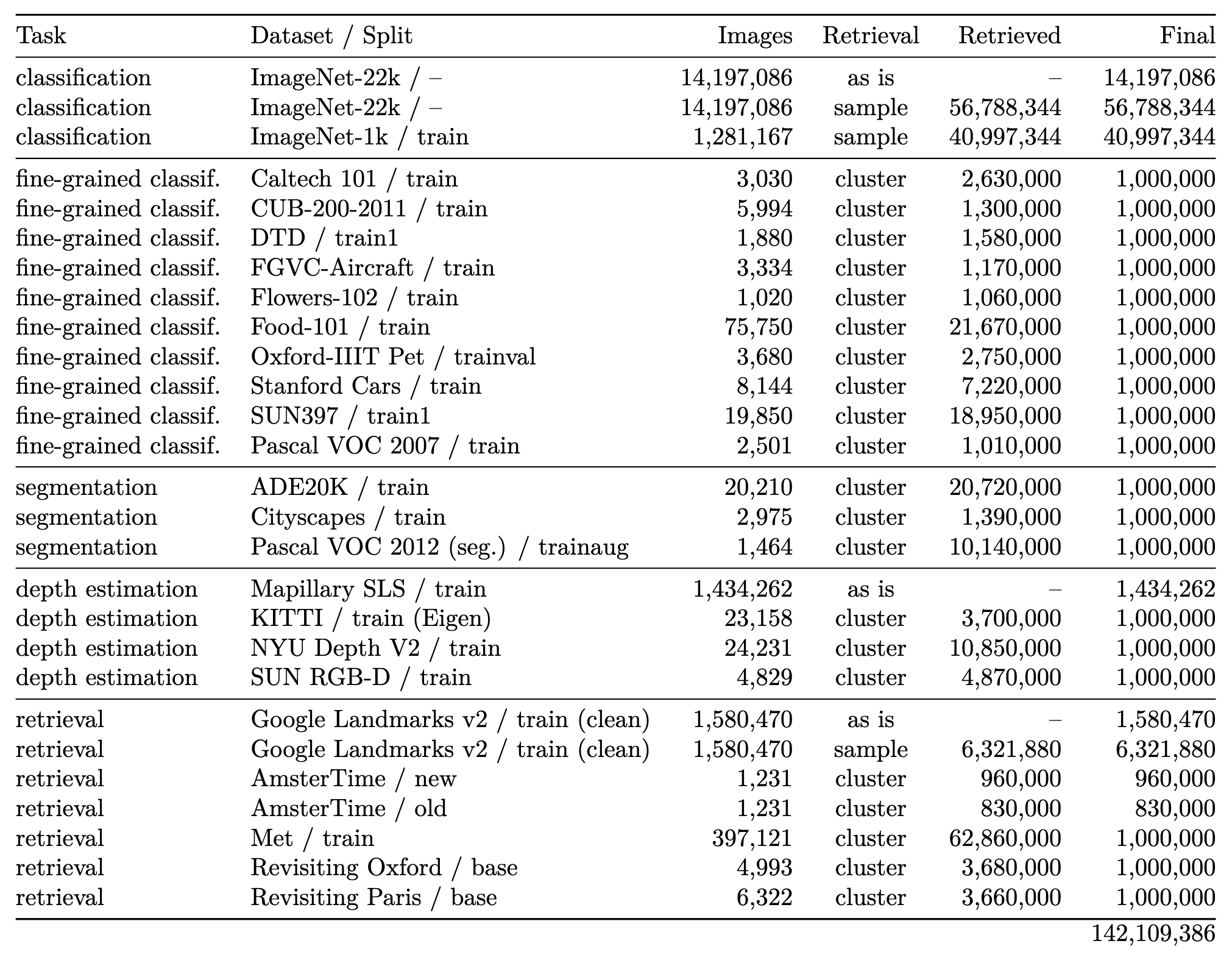
仔细挑选的数据包含了ImageNet-22k,ImageNet-1k的训练集,Google Landmarks和其它一些数据集,未仔细挑选的数据集使用了公开爬取的数据
公开爬取数据包含
标签包含的数据,除去了不安全或域名限制的数据,并进行后处理(PCA hash去重,NSFW筛选,blur可辨认的人脸),获取1.2B图像
使用图像去重方法(https://arxiv.org/abs/2202.10261)去除了近似重复的图像,并去除了与验证和测试集相似的数据
图像检索:
使用在ImageNet-22k上自监督训练的ViT-H/16,并使用cosine相似度计算图像间距离
再对所有未挑选数据集,用k近邻聚类找到与现有数据集相似的图像
如果检索数据很大,对每张图像提取N(4)张
4可以避免一些由于多张检索到相同的图像
如果很小,从簇中采样M张
优势:
约束数据集数据分布,趋近于标注良好的数据集,提升数据集质量
减少数据冗余,并增加数据集的多样性
用Faiss库完成
20个节点的8卡v100-32GB在两天之内完成
对比自监督
DINO和iBOT损失的结合,并使用了the centering of SwAV,增加了一个正则化项和短的高分辨率训练阶段
图像级目标:使用学生ViT的class token,经过DINO head(MLP和softmax)获取,使用教师ViT的class token经过DINO head和移动平均中心化获取,用交叉熵来获取相似度:
教师网络使用EMA进行更新(使用学生网络和过去网络的加权):
patch级目标:随机掩码学生网络的一些patch,使用学生网络的iBOT head来处理掩码token,同样,使用教师网络的iBOT头处理掩码对应的可见token,同样使用于之前类似的softmax和中心化步骤:
不统一head的权重:DINO和iBOT head中都有一个可学习的MLP,在大规模情况下,不共享效果更好
尽管在小规模对比学习中,共享DINO和iBOT head中的MLP效果更好,但大规模条件下不共享权重效果更好(采用相同的head时会出现图像上过拟合,patch上欠拟合的现象,选择不同的head效果更好)
Sinkhorn-Knopp centering:在教师模型上使用3次Sinkhorn-Knopp centering来替代softmax使得更加稳定
KoLeo正则化:可以在batch中得到更均匀的分布
其中,
在计算KoLeo之前,还对特征进行了l2正则化
分辨率:提高分辨率对于像素级下游任务很重要,但很耗资源,由此只在预训练最后引入分辨率的图像
高效实现
更高效attention:使用了FlashAttention,由于硬件实现,每个attention头的维度为64的倍数,总的维度为256的倍数时很高效,由此,ViT-g使用了1536的维度和24head,而不是原版1408维度和16head
Sequence packing:DINO需要在局部裁剪和全局裁剪(输出维度不同),为了高效,将其拼接在一起,同时送入transformer,并使用mask进行隔离,也使用了xFormers库
高效的随机深度:实现了一种改进版本的
stochastic depth方法,它跳过了被丢弃的残差的计算,而不是对结果进行屏蔽Fully-Sharded Data Parallel(FSDP):使用AdamW需要stuent,teacher,optimizer的一阶和二阶动量,将模型副本分片放置在多个GPU中,模型大小不受耽搁GPU内存限制,并且节省通信成本
传统gradient all-reduce operation需要将梯度从不同GPU上收集组合成单个梯度张量,使用float32进行,而FSDP可以使用float16计算
模型蒸馏:小模型是从大模型中蒸馏出来,在蒸馏过程中,与预训练类似,只是将教师网络冻结,移除了mask和随机深度,使用了iBOT loss,用EMA更新
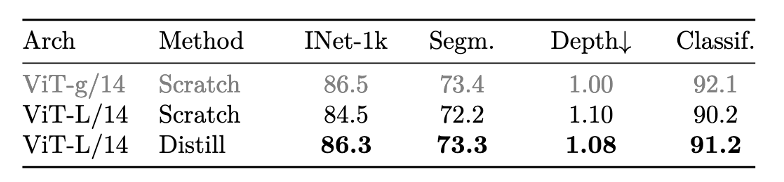
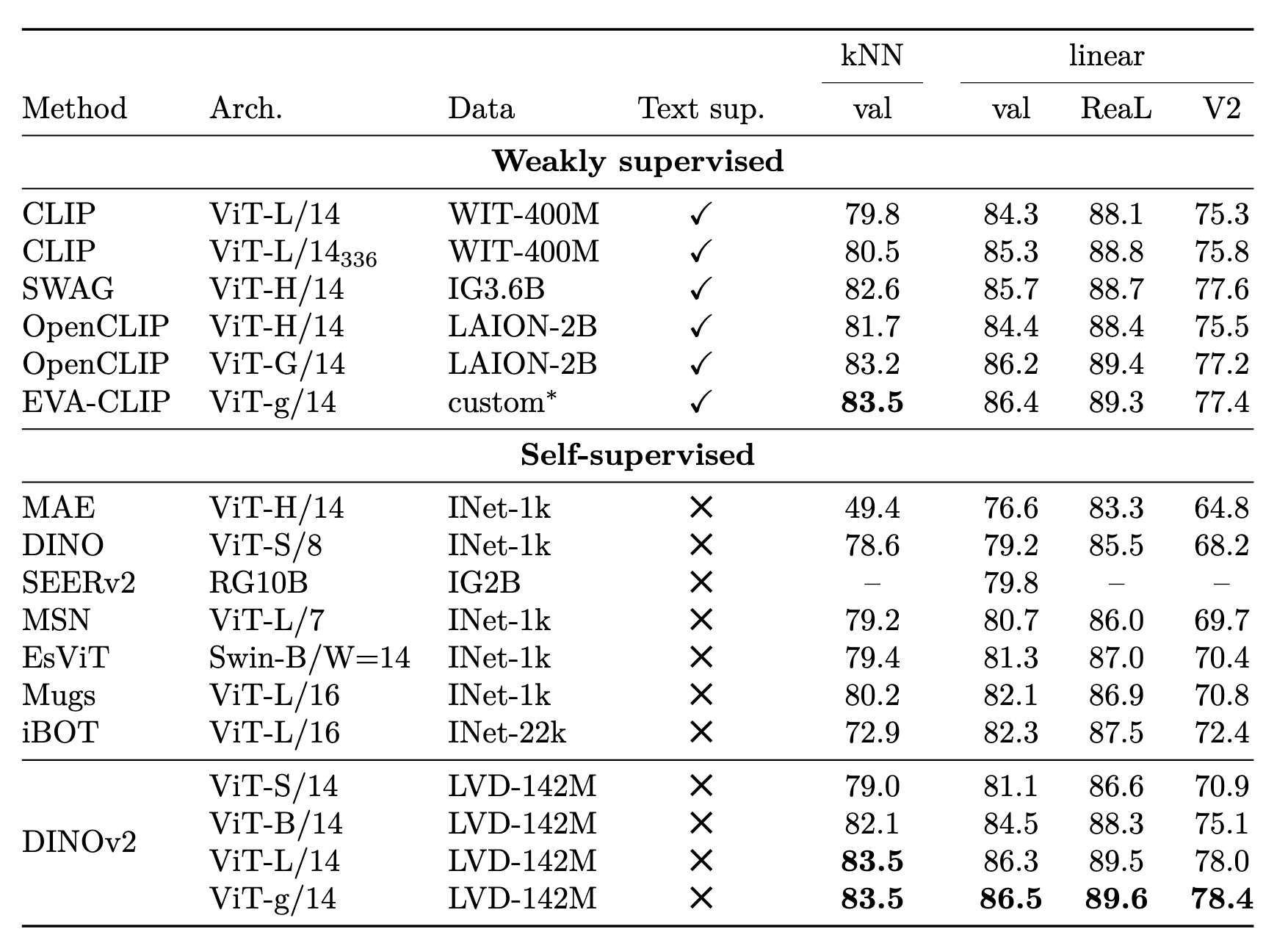
实验效果