[论文笔记] AIM
信息
Title: Scalable Pre-training of Large Autoregressive Image Models
Author: Alaaeldin El-Nouby, Michal Klein, Shuangfei Zhai, Miguel Angel Bautista, Alexander Toshev, Vaishaal Shankar, Joshua M Susskind, Armand Joulin
Year: 2024 Jan
Publish: ICML 2024
Keyword: 自回归,自监督预训练
Code: https://github.com/apple/ml-aim, https://github.com/lightly-ai/lightly
关键词:自回归,自监督,大模型
背景
预训练成为一种标准,一个重要原因是性能可以随着预训练的参数量和数据量不断提升:
- 即使用一个简单的目标,也可以让模型理解长的上下文
- 自回归通常和Transformer一起使用,两者具有协同作用
自回归方法在NLP领域利用简单的代理任务和Transformer架构实现了scaling law(性能持续随着参数量或预训练数据增长)
自回归起源于数据压缩
大规模视觉预训练:
DINOV2证明了合理设计的对比方法性能可以随着规模增大而提升,但达不到语言模型的scaling law,并且依赖于各种优化来保证训练稳定
MAE随着数据的增长(到Billion级别),只有较少的性能提升
文章旨在探索自回归在视觉领域(使用ViT和自回归目标)是否能达到相同的拓展型和性能
贡献:
- 首先回顾了含有ViT的自回归表征学习,大规模web数据的收集,LLM预训练的最新进展
- 为适应自回归预训练引入了两处结构改变:
- 使用了一种T5中的prefix attention,而不是像传统LLM里的attention一样完全自由
- 使用了一个重度参数化的token级的预侧头
无需稳定机制
- 发现目标函数在验证集上的值与后续冻结特征的质量之间存在相关性
预训练数据集
DFN数据集,有12.8B图片-文本对(移除了NSFW内容,模糊和对比验证集进行去重)
使用一个数据过滤网络计算对齐得分,通过保留最高的15%的样本,获取了2B图片,为DFN-2B
使用80%的DFN-2B的数据和20%的Imagenet-1k的数据组成了DFN-2B+
方法
目标
将图片分为K各不重叠patch ,图片的次序被定义为raster次序(从左向右,由上至下)
一个图片的概率可以是patch的条件概率的乘积:
patch的长度固定,不需要截断
训练目标就定义为一系列图像的负对数概率:
预测损失
对于不同分布的,损失可以有不同的选择,默认下,采用了归一化的像素级回归损失(对应了有固定方差的高斯分布)
模型结构
对于scaling,优先考虑宽度而非深度
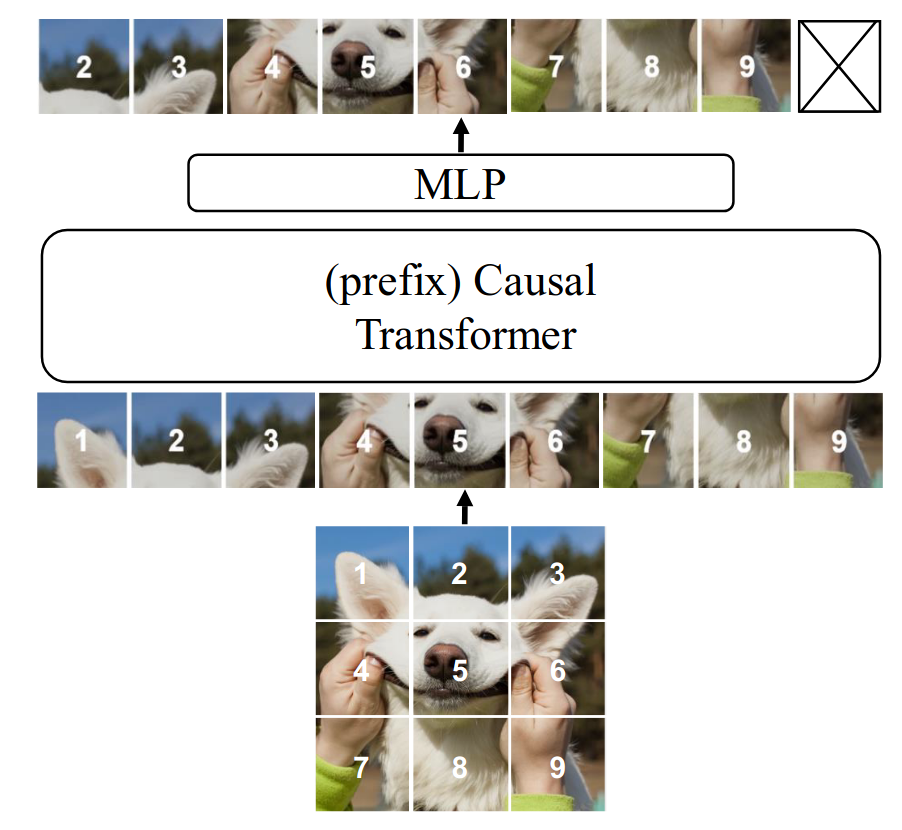
在之前的自回归预训练阶段,在attention层一个因果的mask:
其中, for ,,即所有权重都可以自由的分布在当前patch的embedding之前
prefix transformer
然而,以上的attention并不适用在下游任务中
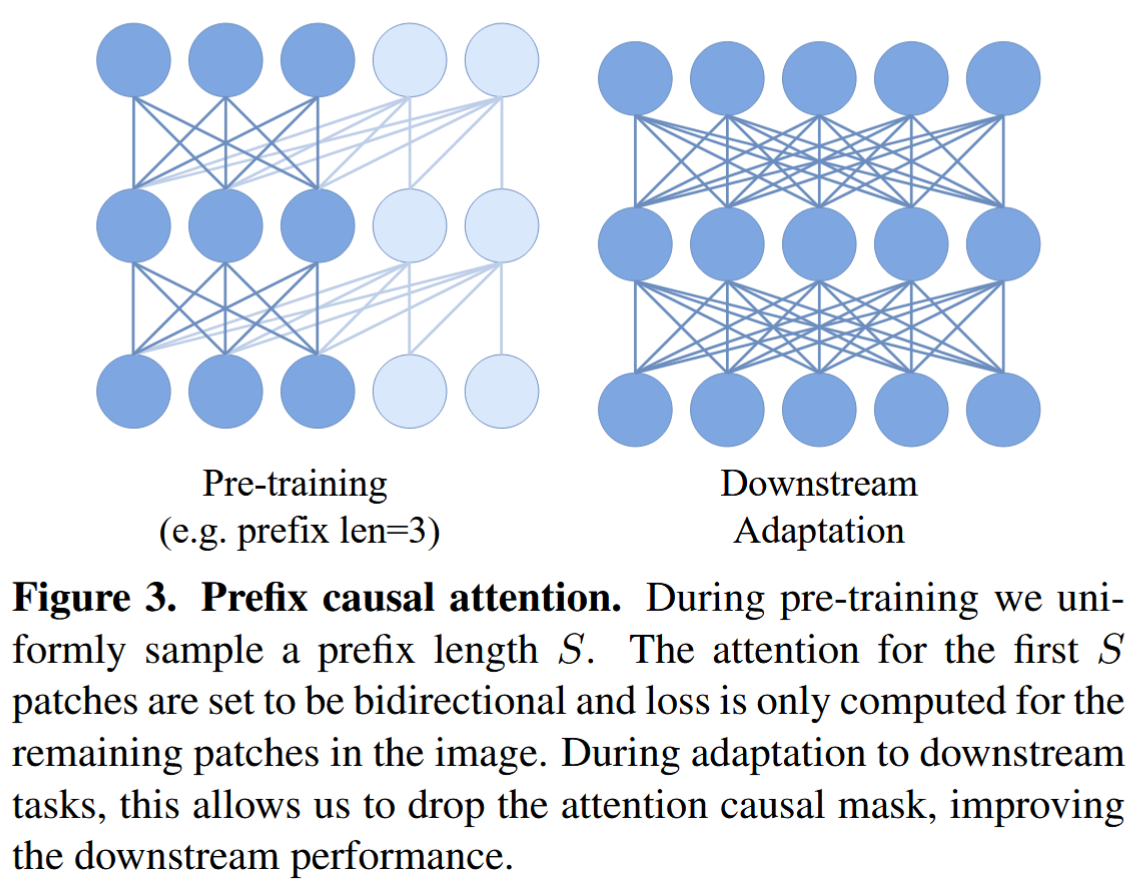
作者提出了prefix causal attention,在预训练阶段采样一个长度的上下文,只使得
a_{i, k}>0$ for $S \in[1, K-1]
这可以使得模型在没有因果mask的情况下工作,在下游任务上不需要改变结构
MLP
通常在预训练阶段使用一个预测头,并在之后去除,保证在下游任务上的迁移效果
使用了N个MLP层,独立处理每个patch,可以很好平衡性能和额外计算
简单设计
不需要诸如LayerScale,stochastic depth,QK-Norm,冻结patch projector来保持训练时的稳定
在Transformer和MLP之前加入正弦位置编码,对 trunk 和 head 中的所有 MLP 块使用标准的膨胀比 4,不使用bias,并且不加入class token,对所有大小都使用12个block
在计算loss前对每个patch进行标准化
使用bfloat16精度,AdamW优化器,使用线性warmup和cosine学习率下降
下游任务微调
只微调分类头
可能在一些小的下游数据集上过拟合,快
由于预训练loss是在patch上进行计算,不会包含任何全局图像的描述
发现和许多生成式预训练方法一样,受益于在线性分类头前的attention pooling操作,对所有patch计算一个全局特征:
对于每个attention头,,是k和v的权重,是一个可学习的权重
最终得到,作为分类头的输入
默认attention头的数量为,可学习参数为,在整个模型中几乎可以忽略
相对于linear probing,这种attention probing的优势:
- 相对少的参数
- 更少的过拟合风险
这表明其可以解决生成式自监督的一个主要问题:缺少图像级的特征
结果
验证集为IN-1k的验证集
scaling
训练时loss大小与性能
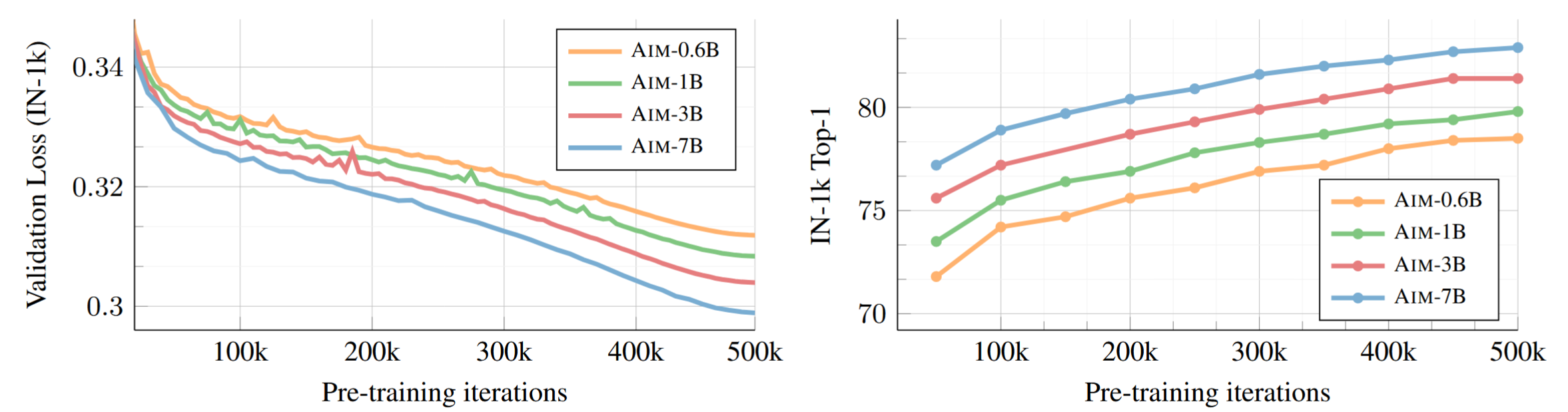
linear probing和attention probing都持续提升了性能
参数量
图像的数量
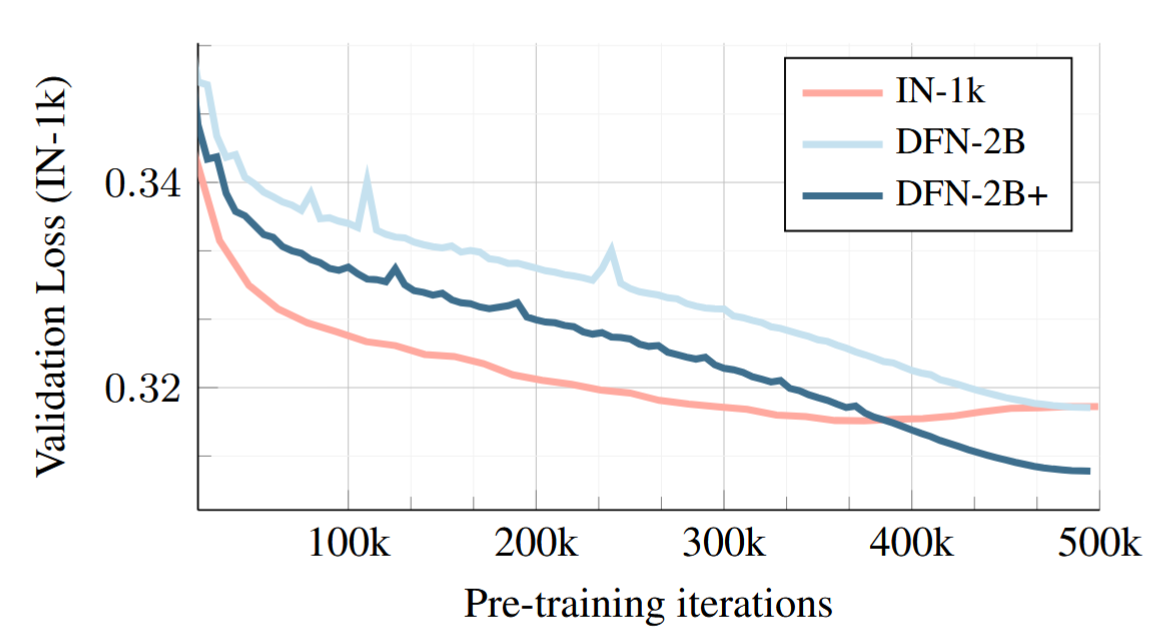
在较小的数据集上验证损失下降很快(IN-1K),但最后却会过拟合
更大的数据集没有过拟合
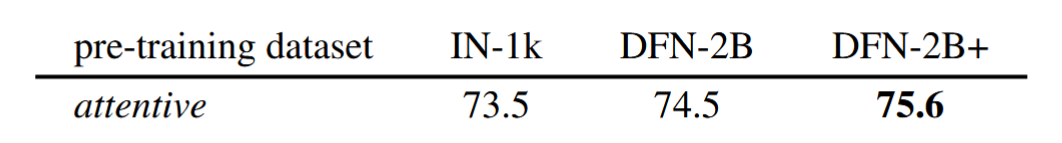
性能也更好
计算最优预训练
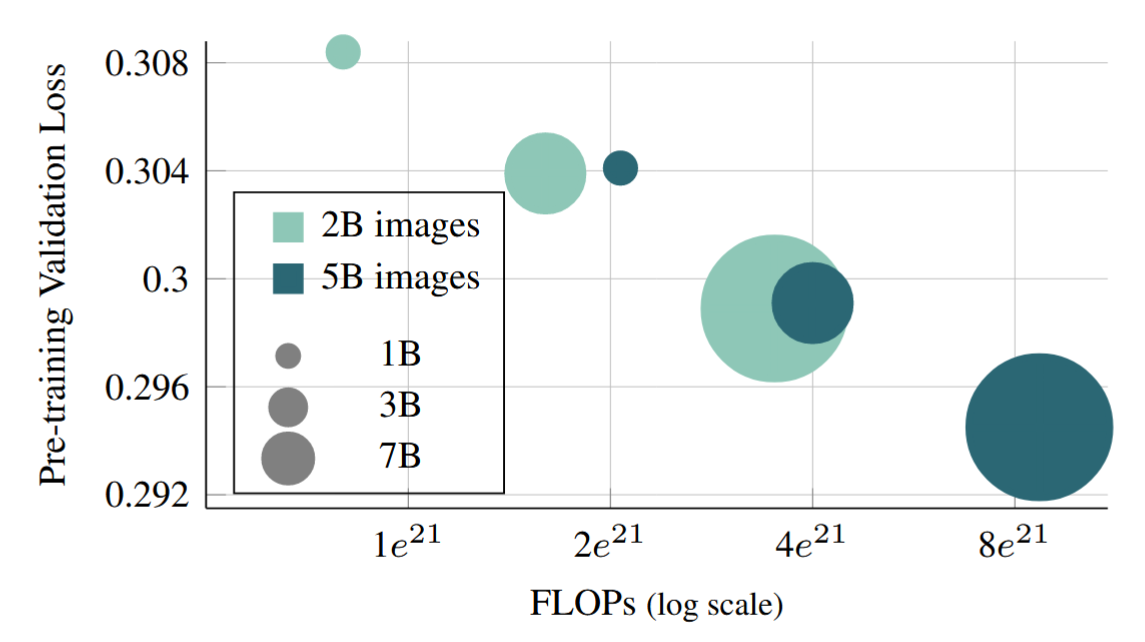
通过延长预训练迭代次数(500k->1.2M次,2B->5B图像),可以获得更低的验证集损失
并且,小的模型训练更长的时间可以得到大模型训练较短时间的验证集损失,但总的计算量几乎一致,与scaling law符合
模型参数
使用AIM-0.6B进,在IN-1k上训练和验证
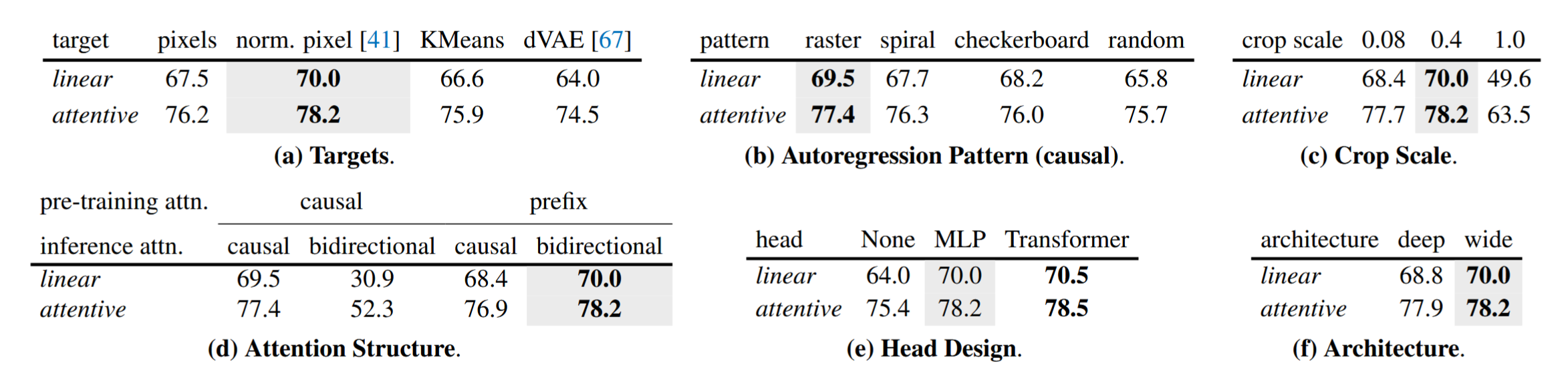
目标
1)像素级MSE损失 2)每个patch归一化的像素级MSE损失 3)patch的离散表征:KMeans,dVAE
自回归方向

patch大小
过小的patch切割可以更容易地预测,过大的patch可能会在较小的预训练数据上过拟合
注意力机制
预测头
预测头用一个MLP就够了,用Transformer提升小而且计算量大
假定这些预测头用来获取准确的像素级预测的低层级信号(与对比学习用预测头防止其预测图像变换类似)
更深或更浅的结构
更宽的结构比更深的结构性能更好,更稳定
Attention probing和Linear probing
attention pooling提供了更好的性能,表明其可以解决生成式自监督的一个主要问题:缺少图像级的特征
MLP的结构
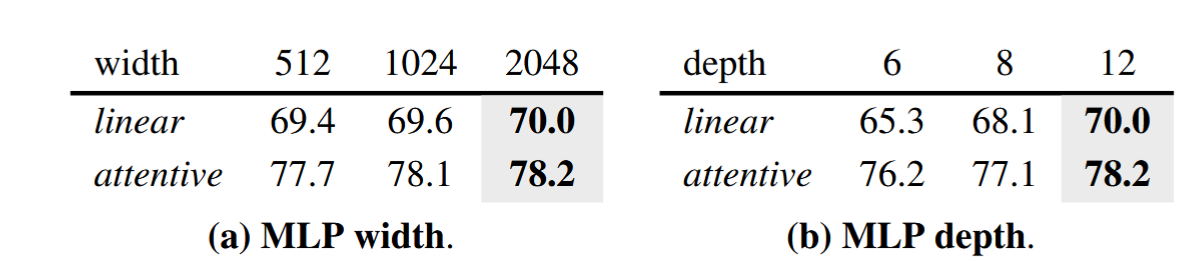
提升深度会带来显著增长,但没有再测试更深,因为会带来不成比例的backbone和head
预训练目标
自回归和掩码
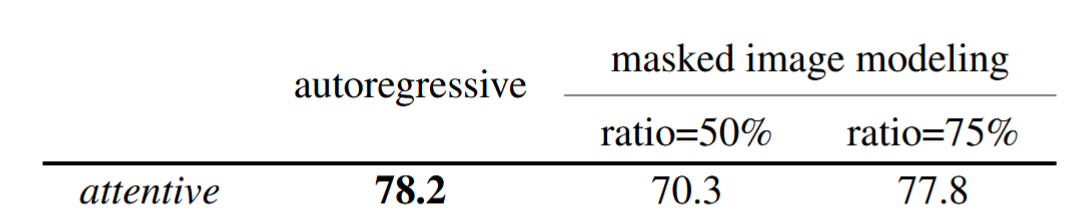
结构相同,都是用AIM
对比实验
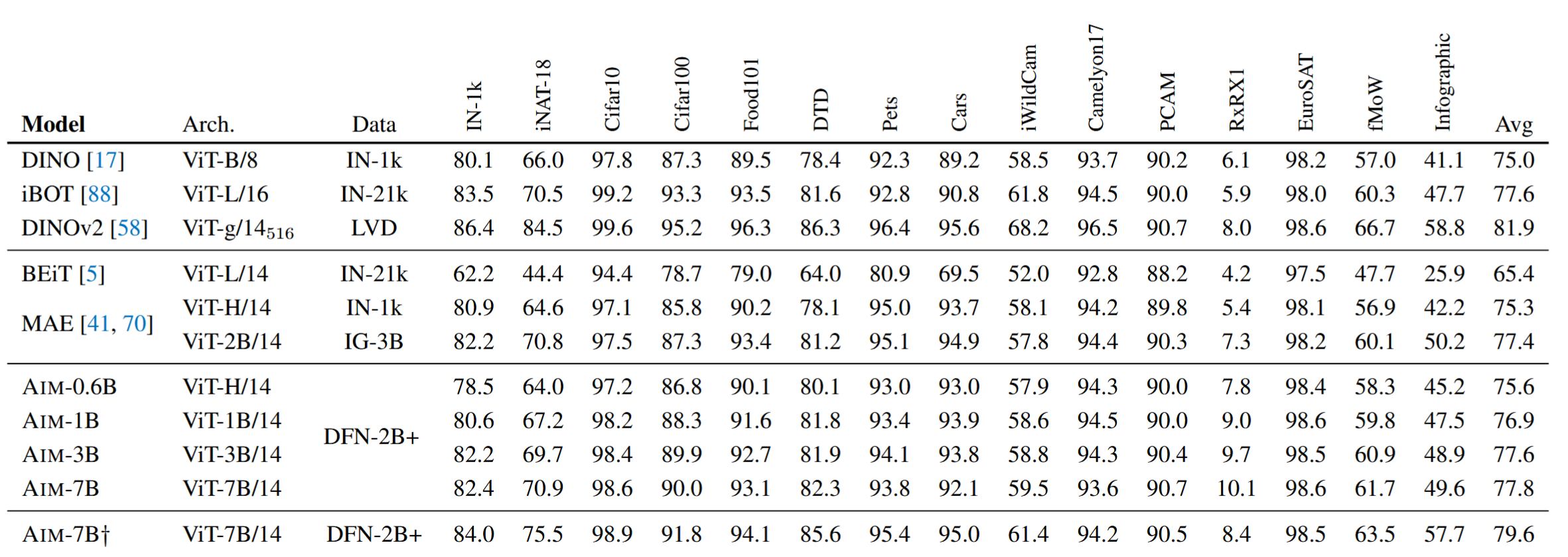
DINOv2使用了更高分辨率的图像,并且依赖multi-crop augmentation, KoLeo regularization, LayerScale, Stochastic Depth, schedules for teacher momentum and weight decay, and high-resolution fine-tuning等技巧
提取更强的特征
对于生成式自监督学习来说,与对比式不同,具有最高层语义信息的特征不一定在最后一层

低秩微调

总结
文章探索了视觉自回归进行大规模预训练,取得了良好的效果,一些结论也十分有用,但是:
- 在许多任务上性能比不上更小的DINOv2