[论文笔记] Web-SSL
信息
Title: Scaling Language-Free Visual Representation Learning
Author: David Fan, Shengbang Tong, Jiachen Zhu, Koustuv Sinha, Zhuang Liu, Xinlei Chen, Michael Rabbat, Nicolas Ballas, Yann LeCun, Amir Bar, Saining Xie
Year: 2025
Publish: arxiv
Organizaition: meta
Keyword: 视觉基础模型,多模态
Code: https://github.com/dfan/webssl
背景
现阶段,视觉自监督比对比式语言-图像预训练(CLIP家族)在VQA任务上落后,可能的原因有:
缺少语言信息监督(模型结构因素):视觉SSL在方法和数据上缺少语言模态的监督,而具有语言监督的多模态模型更偏好VQA
在不同的数据上训练(数据因素):现阶段,视觉SSL通常采用object-centered数据集,而多模态模型采用大规模网络数据集
以往的SSL一般使用ImageNet,ADE20k等object-centered数据集,缺少泛化性,并且无法与其它模型对比
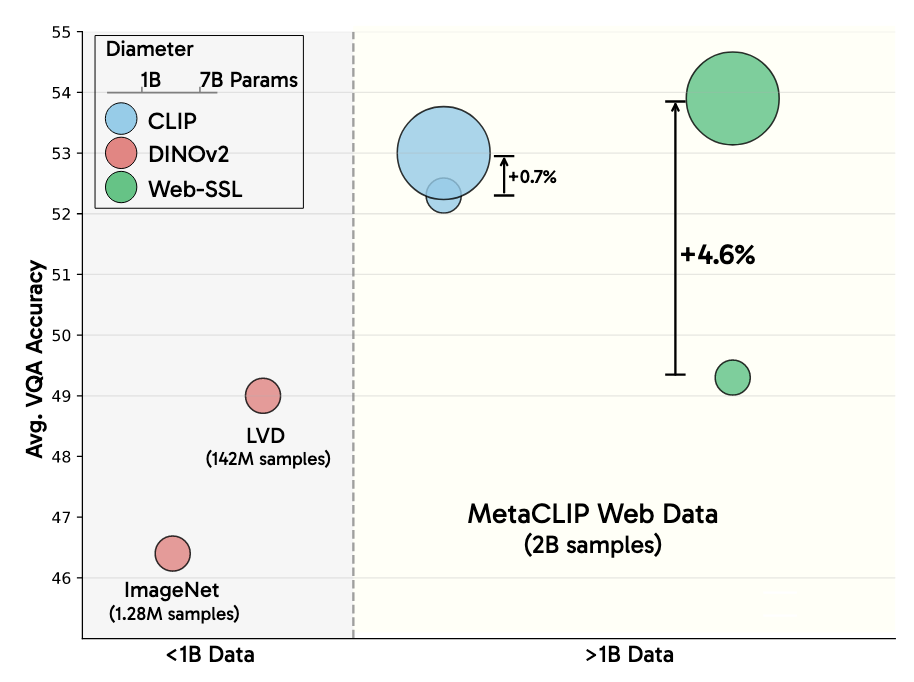
这种语言监督信息是否是必要的?
为了公平起见,对比时使用SOTA的MetaCLIP和其数据集,下游任务上采用VQA(通用,视觉问答,视觉推理,OCR,图表解读。。。),在相同条件设定下对比了视觉SSL和语言-图像模型的性能(VQA和传统图像任务)
贡献:
在VQA任务上,使用相同数据训练的视觉SSL模型比SOTA的CLIP模型表现更好
也有可能是数据在在MetaCLIP处理的时候变得更好,类似AIM对于数据的处理
视觉SSL在模型和数据上scale能力很强
视觉SSL在传统任务上表现更好
以更高的图像比例对OCR,图表理解提升很大
方法
SSL的提升
作者主要在以下方面对SSL进行了拓展,使用了DINOv2和MAE:
将自监督数据集拓展到billion级别
- 使用了MC-2B的图像部分,由此控制数据集分布的影响
但文本不应该也算在分布中吗?
将模型大小拓展到1B以上
- 1B使用ViT-g,2,3,5,7B用其变体
使用更偏向于文本的VQA来进行衡量,而不是ImageNet和ADE20k
- 传统方法会使用Linear Probe进行衡量,还采用了VQA
- 使用了指令微调,数据使用Cambrian-1,LLM使用了Llama-3 8B
- 一层MLP作为模态桥接器进行训练
- 微调MLP和LLM
scaling能力
使用了各自原始的代码(DINOv2没有加入高分辨率)和策略
模型
为了:
- 找到这种数据量上视觉SSL的性能上限
- 看模型是否有任何独特的表现
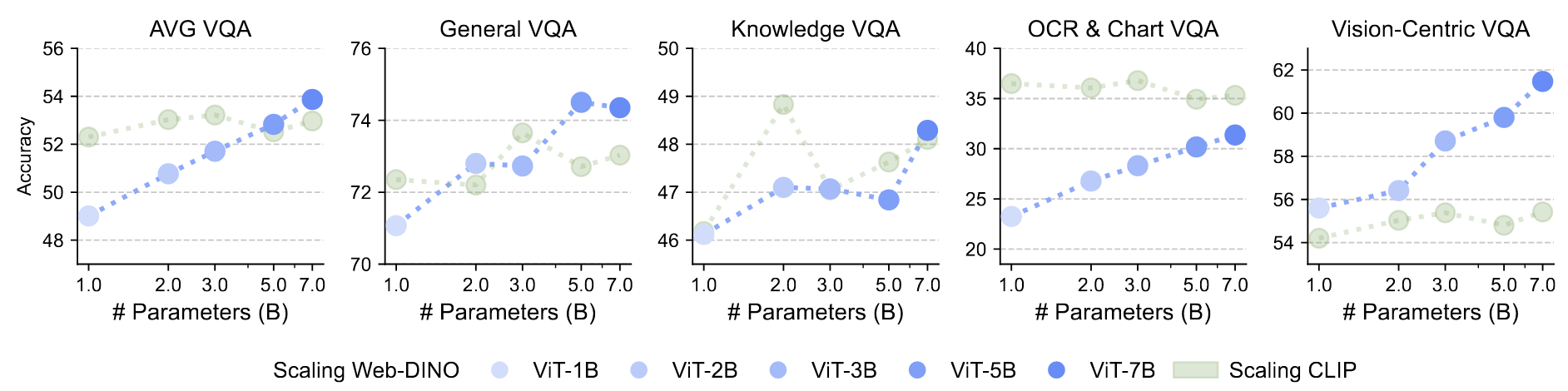
可以看到:
SSL方法大致能随着数据增长,CLIP方法会在3B时达到顶峰,更多的参数会是浪费
SSL方法也没有衰竭,这也说明大于7B的模型也可以探索
那么,在数据分布上的探索也是一个方向
数据
即从1 epoch拓展到0.5epoch~4epoch
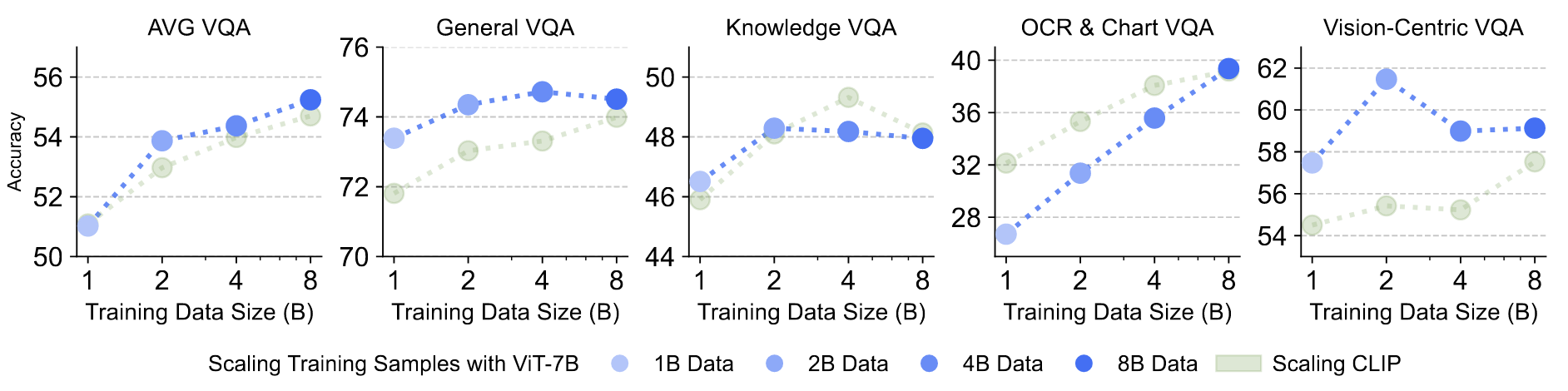
可以发现:
只有OCR一直提升,在没有其它模态损失的情况下,更学习到偏向于文本的特征(更集中)
随着数据增长,也一直比CLIP好
由此,CLIP的语言监督并没有比视觉SSL有绝对优势:
- CLIP的语言监督在偏向于文本任务的VQA上并没有比视觉SSL有绝对优势
- CLIP在传统任务上落后于视觉SSL
问题
是否适用于其它SSL
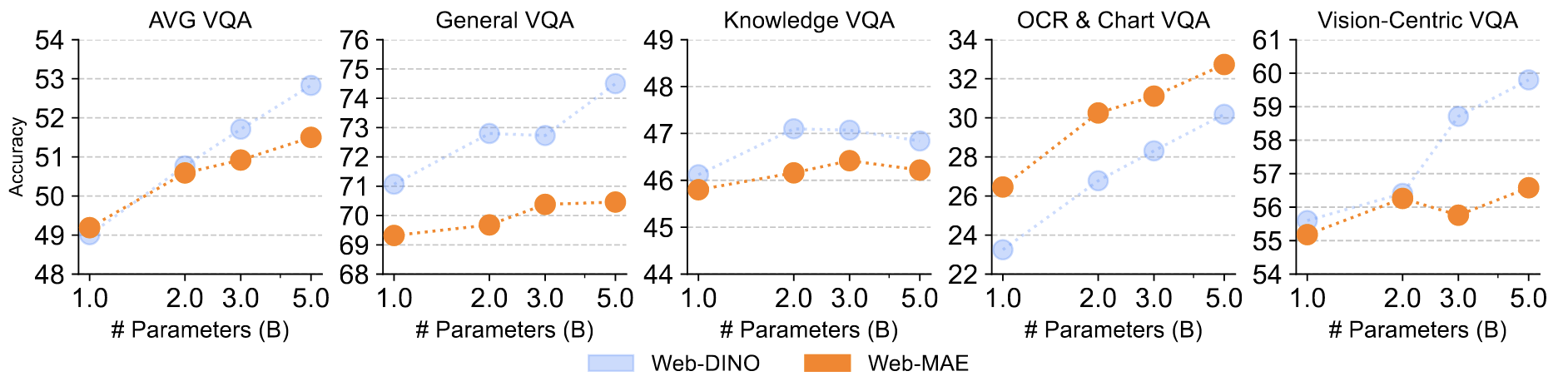
生成式的SSL更适合OCR和图表,但在其它方面不如,整体趋势一致
这也揭示了不同的SSL学习的能力不同
使用传统小数据集是否适用
使用ImageNet-1k进行训练,但性能更差,也没有scaling效果

这也对以前一些自监督方法在ImageNet-1k上自监督训练的结果提出了质疑
表明数据集的更多元化,更大对于模型性能的提升,并且预训练数据集分布也会对下游任务影响很大
在传统任务上表现
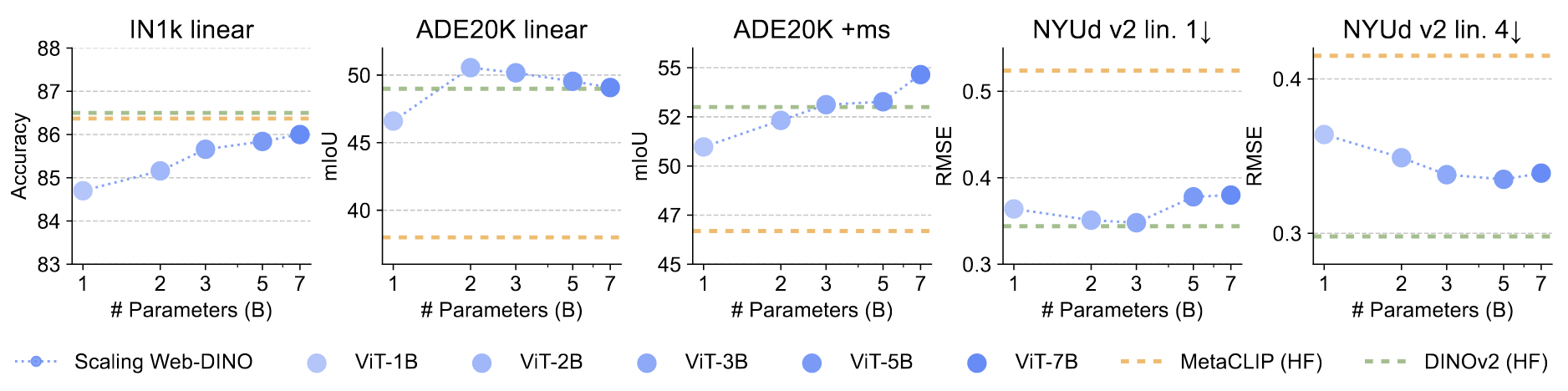
- 比CLIP模型效果显著要好,也没有比DINOv2差多少(在没有高分辨率和DINOv2数据更接近传统任务的情况下)
但DINOv2最大是1B左右的
- 但在传统任务上scaling表现没那么好
这也表明VQA作为一个更多元化任务的衡量
在OCR,图表任务上的提升
- 传统数据上不含表格,文档,网络数据上包含文档,文字

50.3%去除了不含文字的图片,1.3%只包含表格,文档。。。
而且更奇怪的是,遮挡掉数据会提升整体性能
为什么缺失语言模态
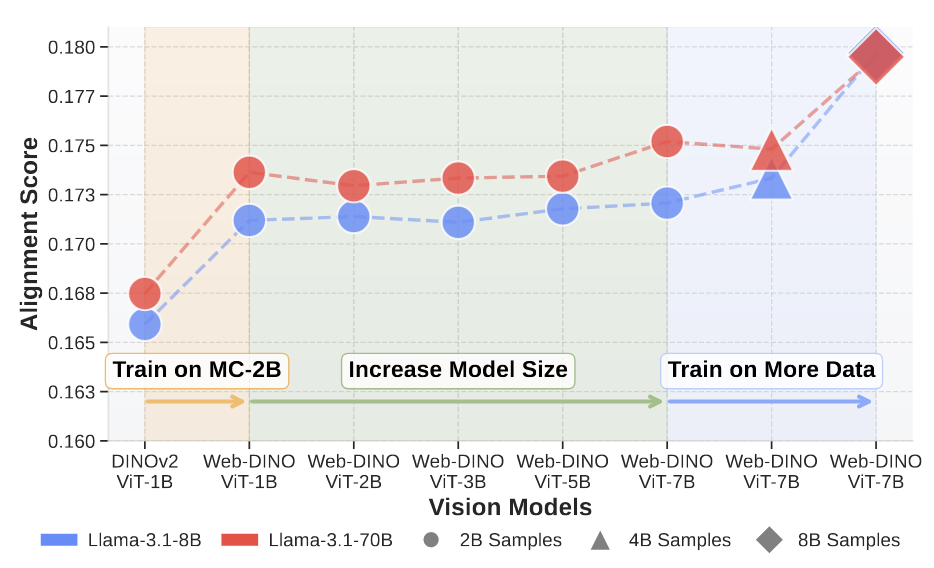
计算了模型的对齐分数,趋势:
- 在更广泛数据集上,对齐分数更高
- 更大的模型对齐分数稍微更高
- 更多的数据对齐分数更高
其实无论文本还是图像,都在追求一种更广泛而更紧密的特征表达,由此对齐分数更高
实验
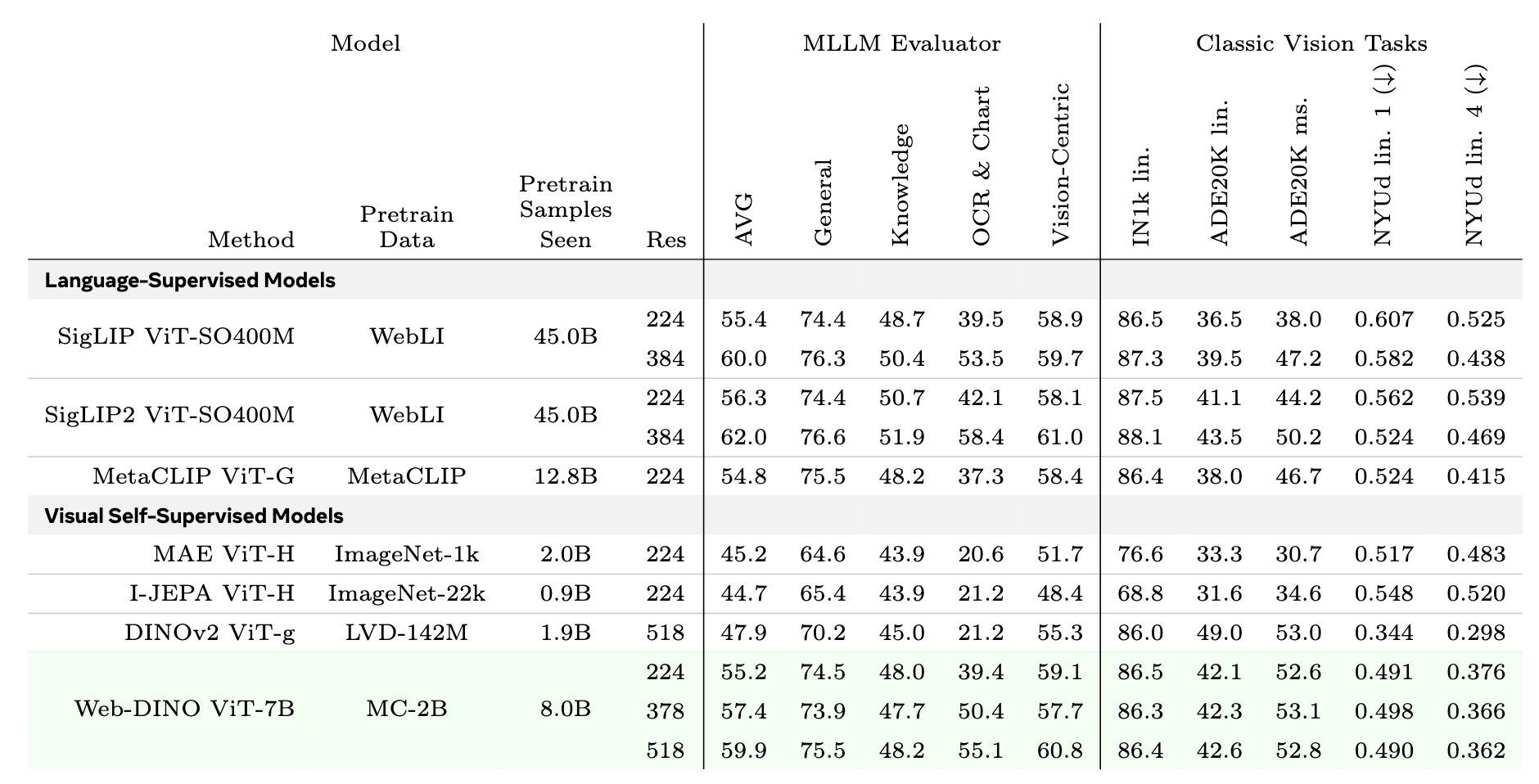
总结
文章围绕语言监督信息是否是必要的?的问题展开:
进一步训练数据探索的可能----多样性,分布,数据规模,图表。。。
视觉SSL任务对比CLIP家族在很多方面(即使是更偏向于文本的VQA)还有优势,多模态大模型的视觉组件更可以利用视觉SSL探索进行构建
但存在一定局限:
不支持零样本(需要对齐文字支持零样本学习)
虽然超越CLIP,但在许多任务上比不上DINOv2
只使用了Llama-3 8B Instruct,假定LLM不会带来影响
数据和模型大小局限