Jetson+gemini 2相机配置教程
Jetson平台和Gemini 2相机平台
Jetson Orin NX/Jetson AGX Orin
NVIDIA Jetson™ 是专为机器人和嵌入式边缘 AI 应用打造的平台,设计紧凑但功能强大的计算机,并由NVIDIA JetPack™ SDK提供支持,能够加速软件开发。
产品次代:原始系列->Xavier系列->Orin系列->Thor系列(未来推出)
等级:Nano,NX,AGX
完整规格表:https://www.nvidia.cn/autonomous-machines/embedded-systems/#jetson-compare
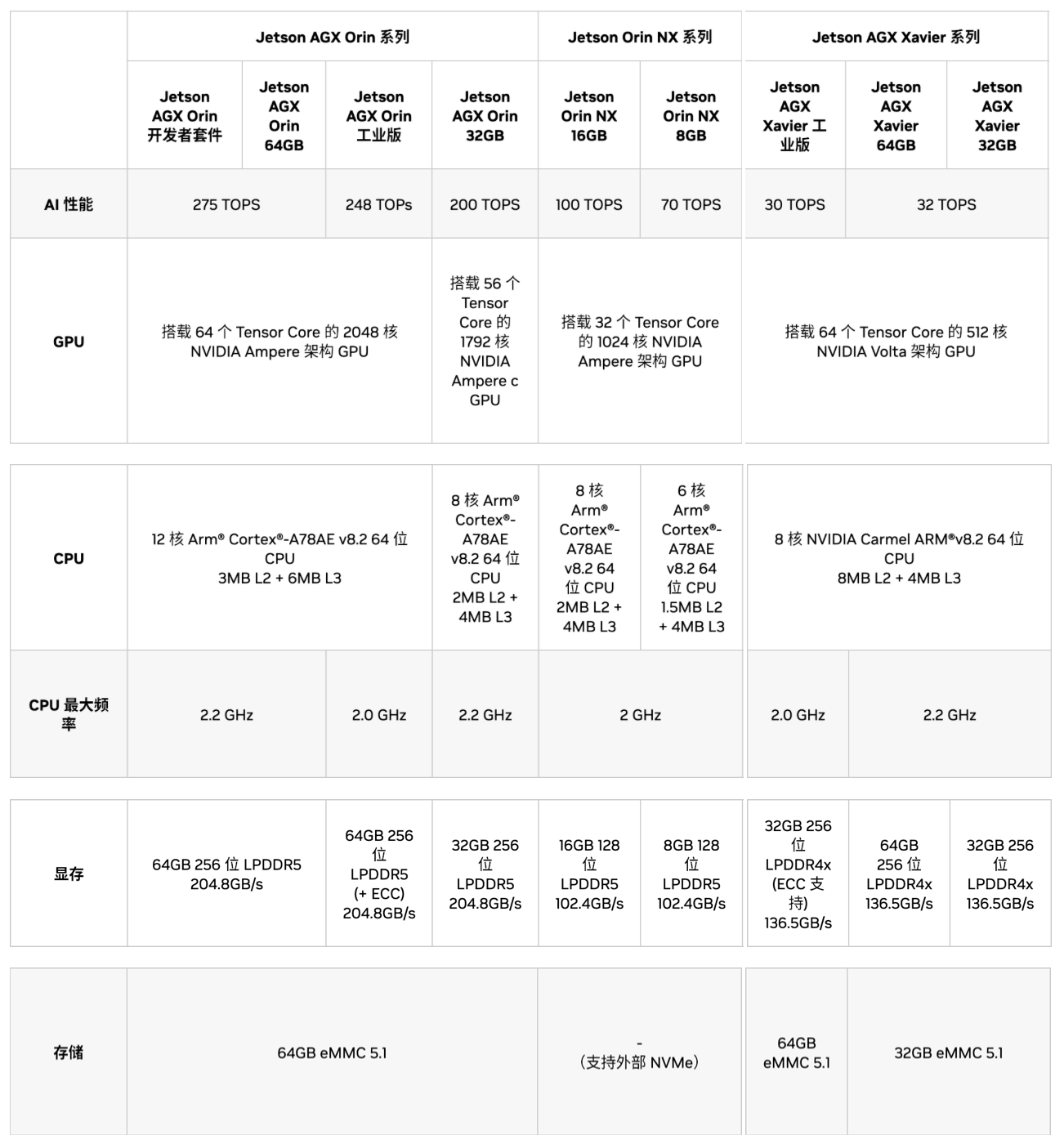
AI性能:可以横向对比在GPU上运行程序的速度,例如目标检测,分类等,但值得注意的是,这里是指理想情况下(最大功耗,合适温度条件下)的最大性能(INT8精度)
CPU:可以横向对比在CPU上运行程序的速度,例如图像采集,流程控制等
显存:与传统计算机不同,Jetson的内存类似于手机,CPU和GPU共用显存,显存决定了能跑多大的模型,跑多少程序等
存储:可以安装系统,存储文件等等,但在实际使用中,eMMC存储通常只用于调试,不推荐使用eMMC存储在生产环境中(容易),强烈建议增加NVMe存储
选购建议:可以根据显存进行选择,可以查询所使用的模型需要多少显存运行,在此基础上+4G(用于系统运行控制等)显存的规格就可以
一般来说,只要任务不是太离谱,速度都可以通过软件优化满足,当然,花钱解决也是一种途径
越大规模的功耗一般更高,可能会不满足使用条件,这也是要考虑的一点,由此选择越小的会越稳定
Gemini 2
奥比中光Gemini 2是一款双目结构光3D相机,集成了光学,红外,IMU传感器,可以提供RGB和深度图像。
完整规格表:https://www.orbbec.com.cn/index/Product/info.html?cate=38&id=51

Gemini 2为开发者提供了SDK,可以为开发者处理一些烦杂的底层调用,专注于软件的开发,可以参见其文档:
https://github.com/orbbec/pyorbbecsdk/tree/v2-main
pyorbbecsdk推出了v2版本的sdk,Gemini 2和335更推荐使用v2版本的SDK
https://orbbec.github.io/pyorbbecsdk/index.html
如果熟悉c++还可以查到底层的一些API接口,一般在python中都有对应的绑定实现https://orbbec.github.io/docs/OrbbecSDKv2/index.html
当然,其也支持一些Linux下标准的硬件控制,可以利用标准接口和厂商的接口实现一些高级功能
Gemini 2提供的输出有:
RGB图像帧
深度图像帧(可以与RGB图像同步)
红外图像帧
空间坐标和加速度
值得注意的是,由于IMU的频率过高,输出的空间坐标和加速度可能存在与图像帧对不上的问题,如果需要使用的话需要经过后处理
其中的SDK还提供了一些非常有用的功能:
- RGB图像帧与深度图像帧同步(硬件/软件)
- 自动曝光,对焦控制
- 镜头保护
平台搭建
现代嵌入式设备已经发展得相对复杂,性能也有了极大的提升,面向任务也会更加复杂,除了一些极端环境,已经不需要考虑直接控制设备进行板级开发,一般使用硬件提供的平台或者SDK去完成对应的任务
板级开发一般涉及到内存管理,设备地址读写等操作,正确配置可以在资源极端情况下做到更好的性能
Jetson系统配置
版本选择
NVIDIA官方对Jetson设备提供的软件支持是L4T BSP(板级支持包,包括底层驱动,GPU控制等)和JetPack(软件环境,包括CUDA,CUDNN等上层工具),其包含了运行在一个定制Ubuntu系统上的一系列软件。
BSP和JetPack都可以通过Nvidia SDK Manager完成安装,需要注意的是,SDK Manager只能在Linux环境下运行,并且,对于系统版本有明确的对应要求:

注意,软件和内容的下载可能需要科学上网
另外,JetPack的版本对于所运行的设备次代也有要求:
- JetPack 4.x支持的设备为Jetson Xavier NX 系列、Jetson TX2 系列、Jetson AGX Xavier 系列、Jetson Nano、Jetson TX1
- JetPack 5.x支持的设备为Jetson AGX Orin 系列、Jetson Orin NX 系列、Jetson Orin Nano 系列、Jetson Xavier NX 系列、Jetson AGX Xavier 系列
- JetPack 6.x支持的设备为Jetson AGX Orin 系列、Jetson Orin NX 系列、Jetson Orin Nano 系列
整体上就是4支持原始系列,5支持Xavier系列,6支持Orin系列,可以按照这个选择
尽管可能有其它支持,例如5支持Orin系列,但实际支持并不完整,有许多BUG,对于上层软件也有一定限制,因此尽可能按照上面选择
如果你清楚自己在做什么,那么可以使用命令行的方式进行安装,可以参照https://docs.nvidia.com/jetson/archives/r36.4.3/DeveloperGuide/IN/QuickStart.html#to-flash-the-jetson-developer-kit-operating-software
因此,对于所使用的Jetson Orin NX/AGX Orin,所选择的上位机系统为Ubuntu 22.04,JetPack版本为6.2
烧写系统和组件
首先需要将Jetson,将开发板与上位机连接,并连接网络,设置为恢复模式,然后打开SDK Manager
对于Jetson NX来说,需要利用杜邦线连接Rec Mode和GND阵脚,然后通电
对于Jetson AGX来说,按住Rec按钮,然后点击电源按钮开机

通常来说,只需要选取Jetson系列,Jetson模组(一般无需在上位机上安装软件)进行安装,如下图所示:
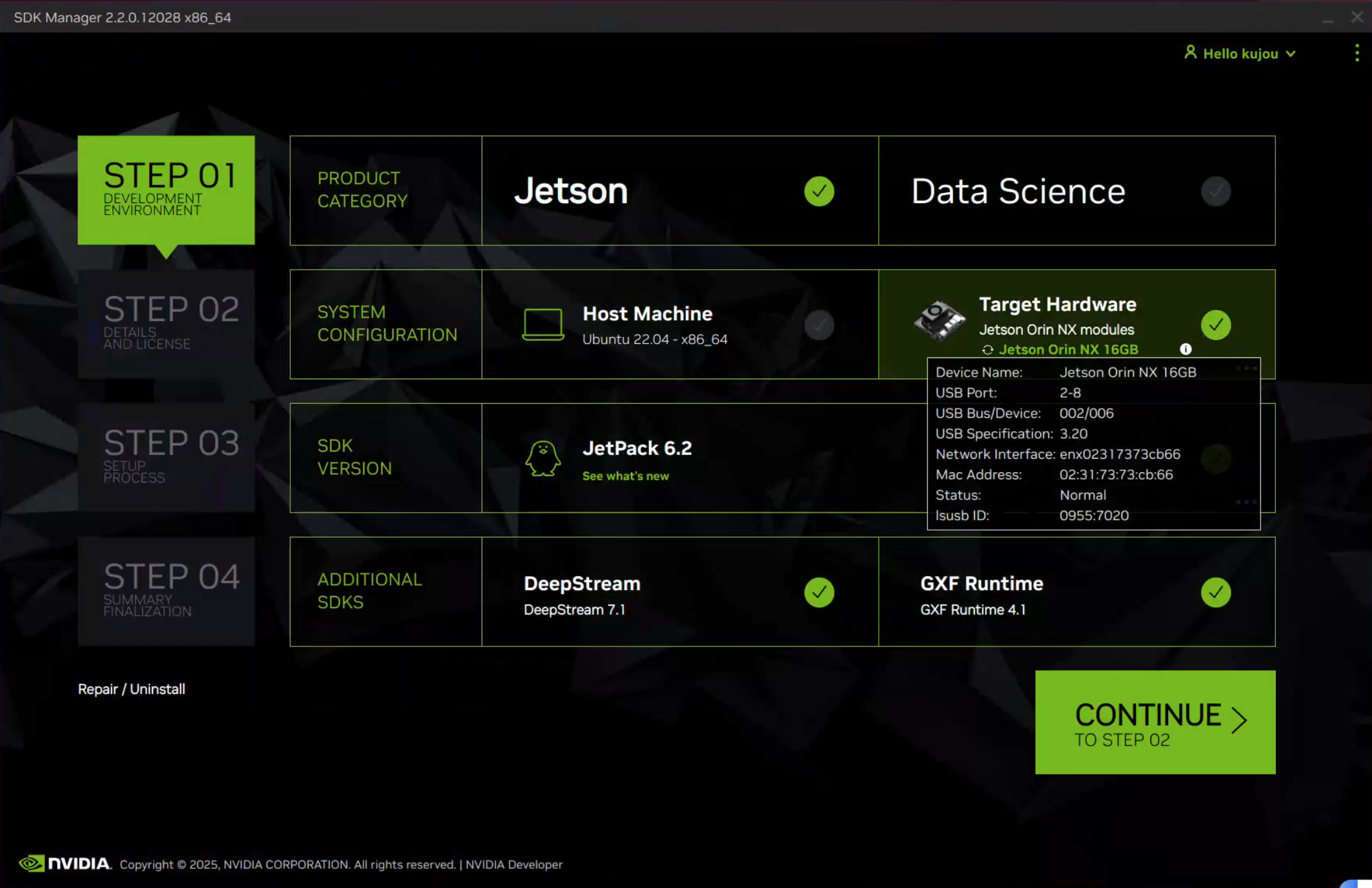
然后,在第二步选择具体组件开始烧写(可以选择全部,避免之后重新安装)
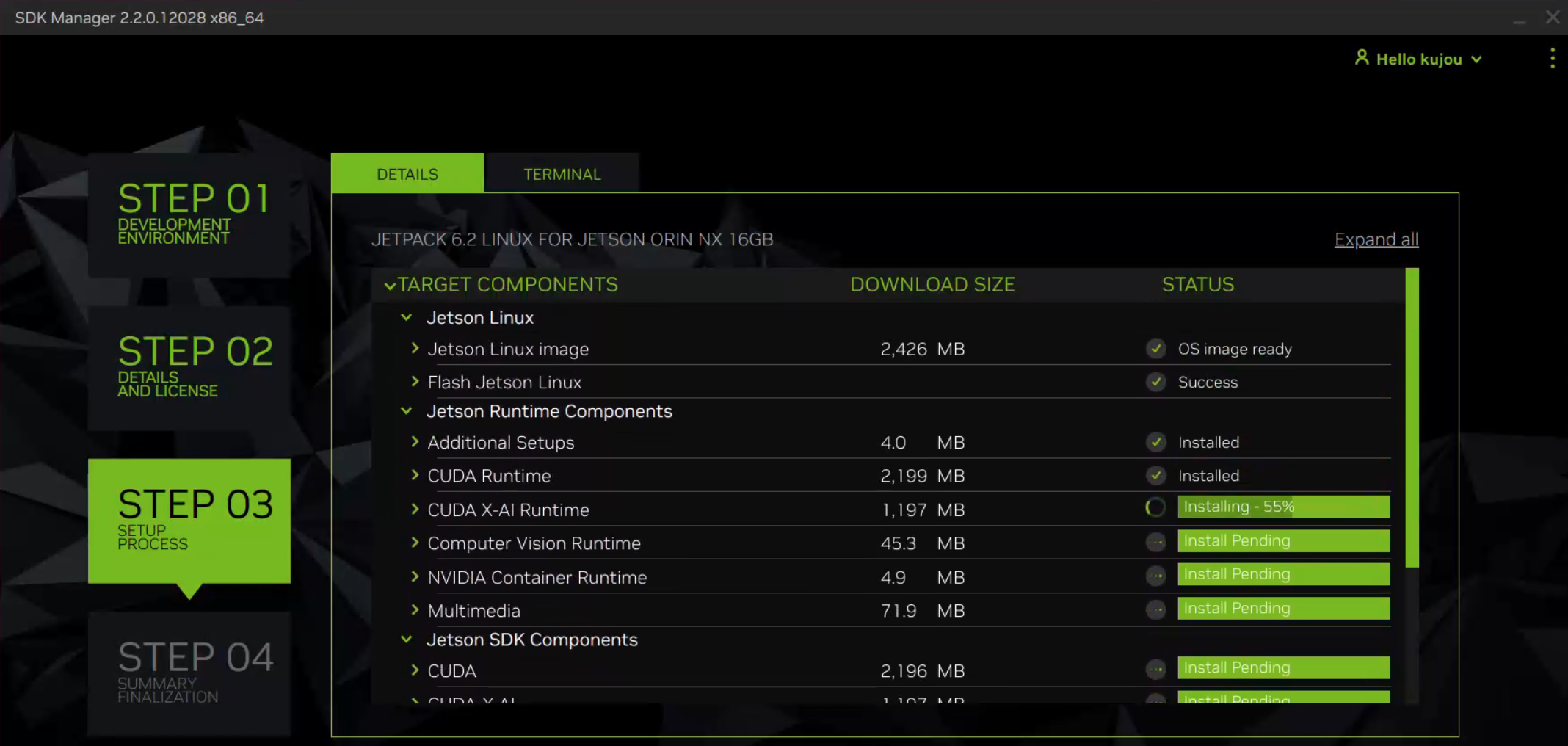
中途会让你设置用户名和密码,填入即可:
对于其中的IP地址,可以保留默认的192.168.55.1,即直接通过usb连接,也可以在路由器中查到开发板的ip地址
一般OEM配置选择Pre-Config,runtime会在烧写完成后第一次开机进行配置
对于存储介质选择,AGX需要选择板载的eMMC,然后在烧写完成配置nvme或者利用工具迁移到NVMe硬盘上,否则可能导致烧写失败
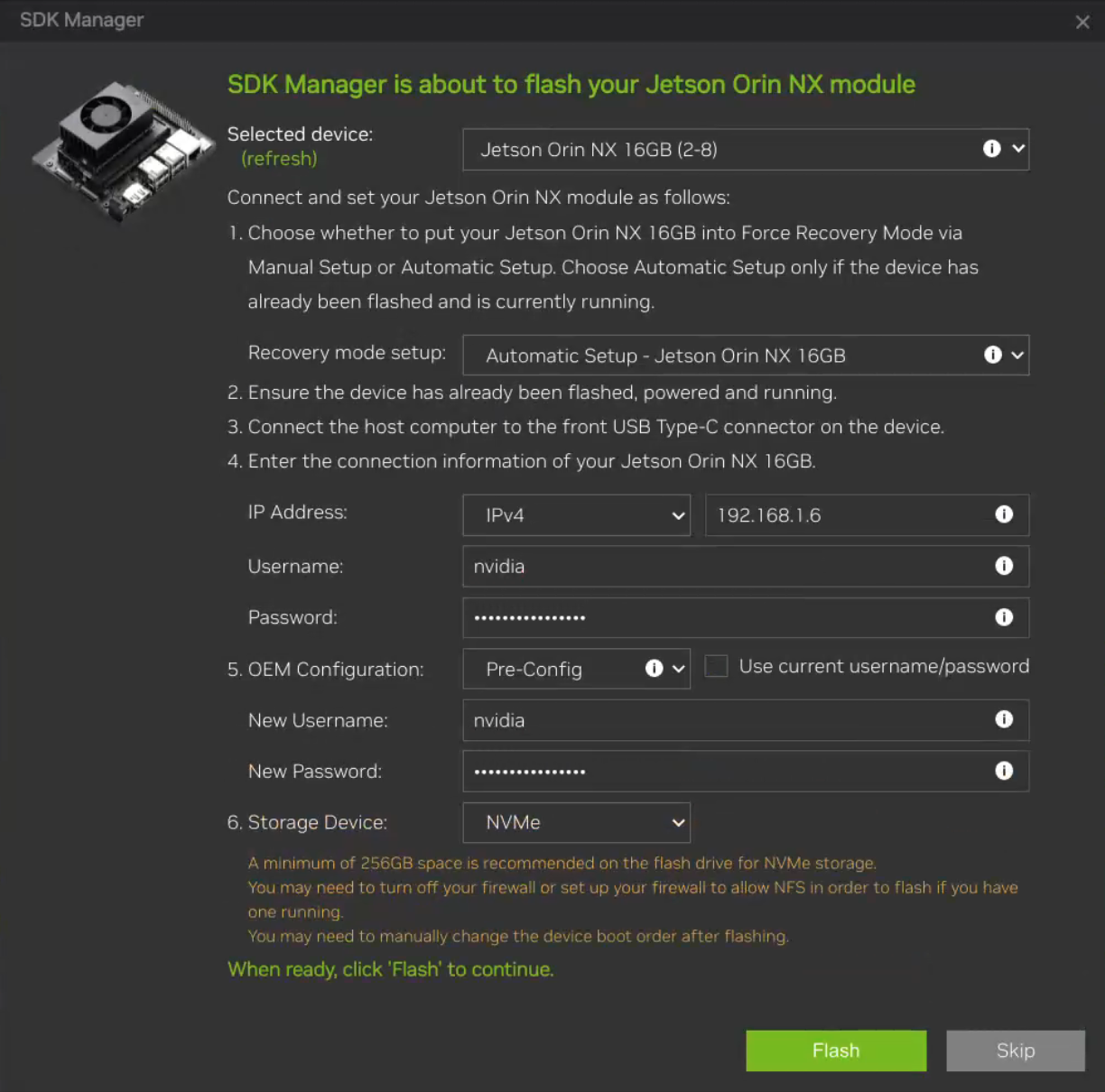
很多时候,由于网络问题和上位机与Jetson的连接问题,会导致烧写失败,可以重复上述步骤,如果持续错误,需要确认是否有步骤错误或者在官方论坛询问
等待烧写完成之后开机即可
初始化配置
和许多Linux系统一样,Jetson同样支持界面模式(graphics mode)和命令行模式(head-less mode),在开机时,Jetson会检测视频输出接口(DP或HDMI)是否接有设备,如果没有,就自动进入命令行模式
命令行模式下,无法启用界面模式,VNC等界面相关组件也不可用
在插入视频接口的情况下,使用界面模式,如果需要使用到界面模式的功能,在完成初始设定后,需要额外:
确认网络连接
关闭屏幕保护和休眠,在右上角设置的隐私中,可以看到屏幕选项,关闭相关设置,否则可能会引起一些故障
在没有插入视频接口的情况下,直接进入命令行模式,没有图形界面输出,可以使用ssh登陆系统,用户名和密码为之前的设置
如果你熟悉linux,对于系统更新,可以进行更新,最好不要执行apt autoremove命令来清除多余的包,可能包含一些SDK Manager的包,如果不熟悉linux,可以不进行系统更新
一些基础的Linux教程可以参考https://www.runoob.com/linux/linux-tutorial.html
VSCode连接
对于开发板的开发来说,可以在上位机上使用VSCode进行开发,这样只需要网络通畅,就能随时随地进行开发,可以在https://blog.csdn.net/qq812457115/article/details/135533373找到如何进行
安装jtop
jtop是一个专属于Jetson系列的性能监控,配置工具,极其推荐安装,使用以下命令:
1 | sudo pip3 install -U jetson-stats |
值得注意的是,由于需要获取系统配置,需要重启之后才能使用
其界面如下,实时显示了系统的信息和负载情况,可以使用键盘和鼠标进行控制
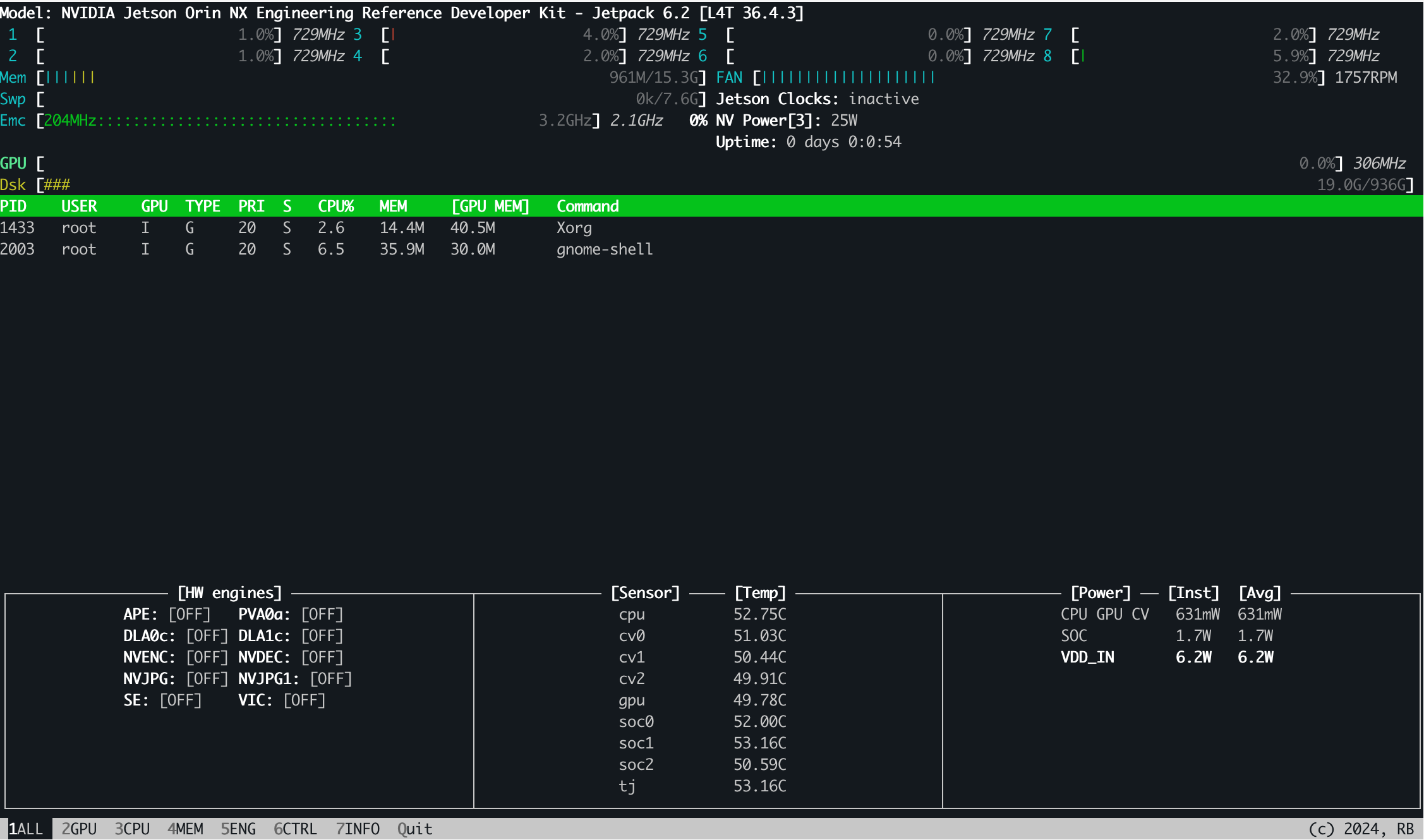
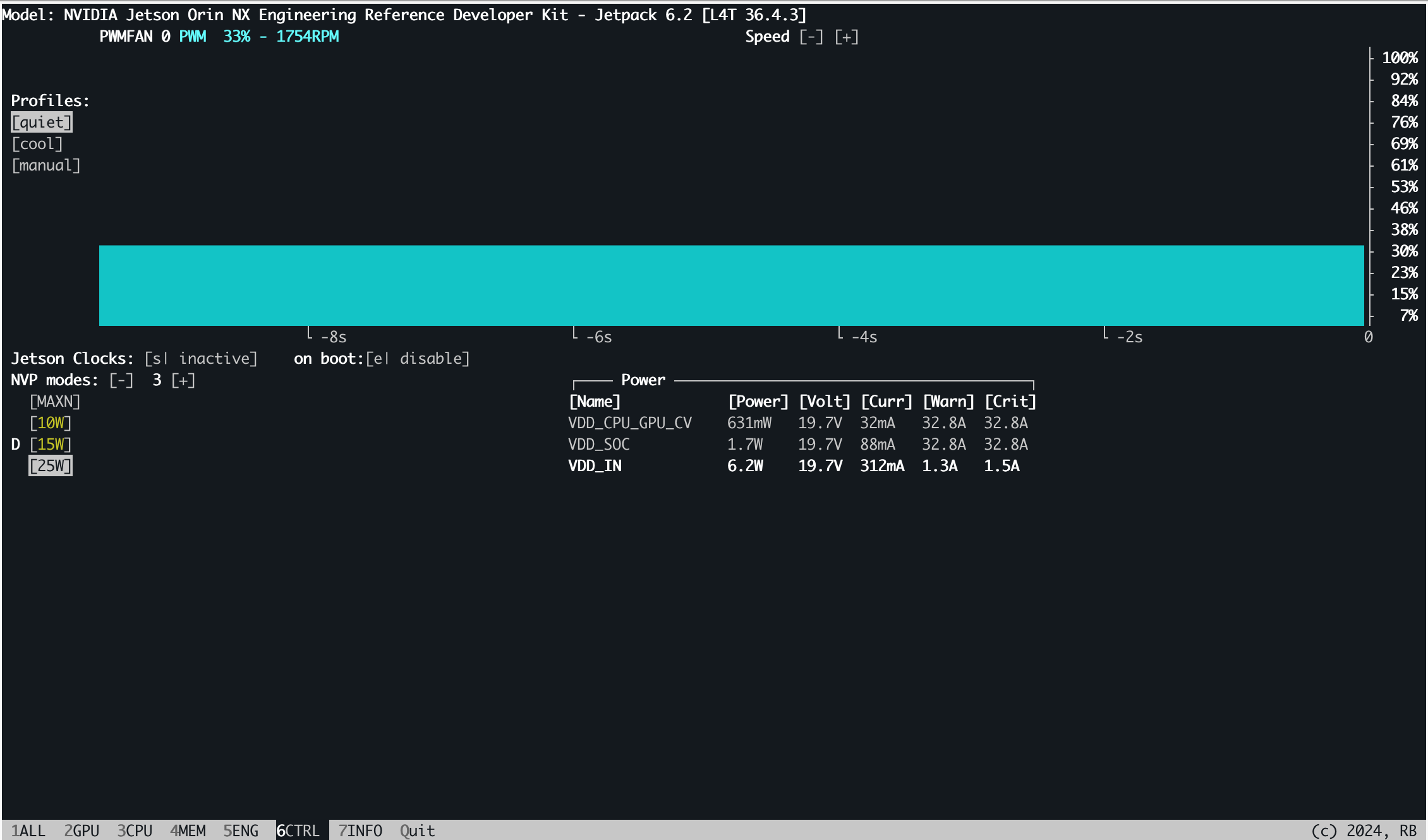
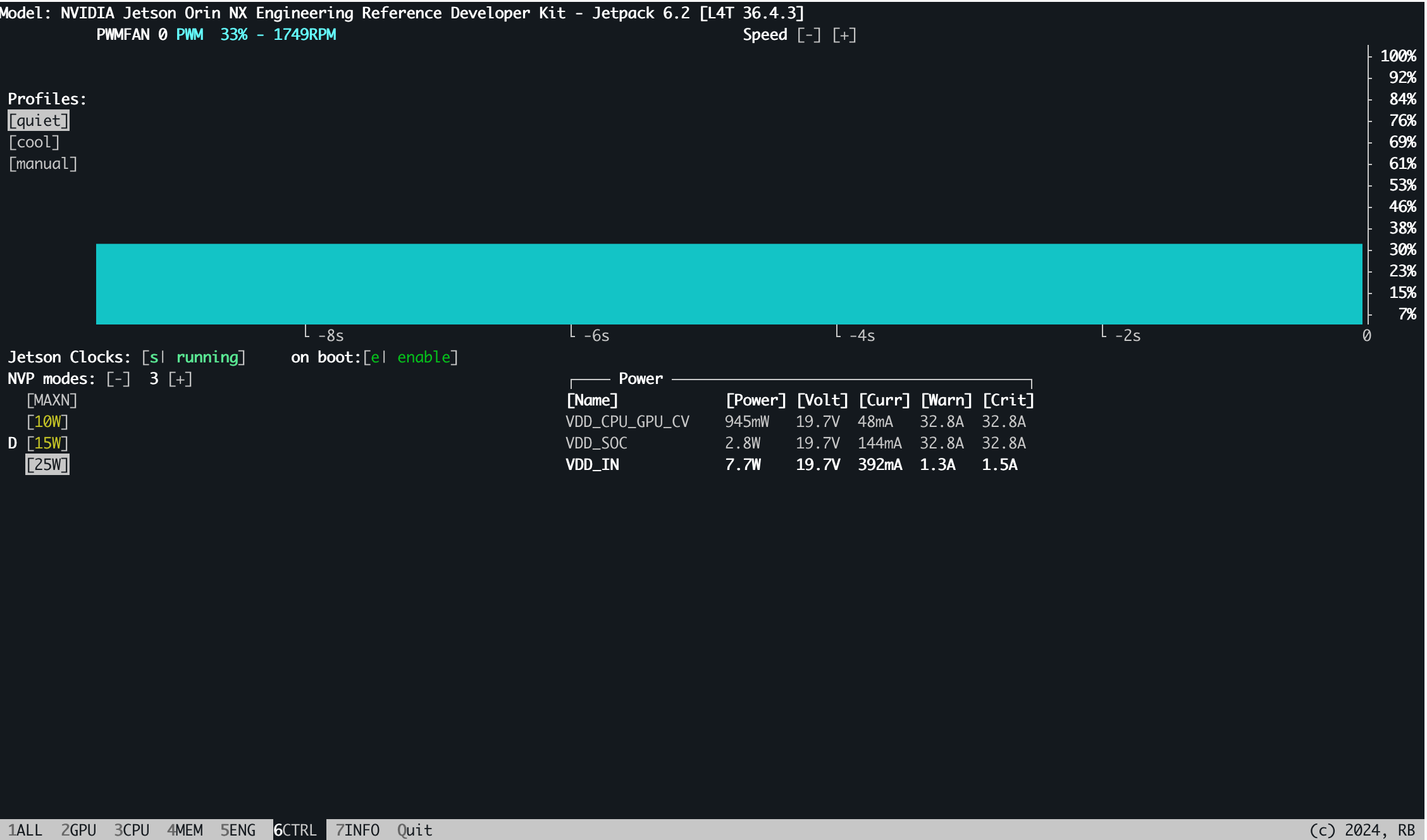
在6.CTRL中,我们对系统状态进行控制,打开Jetson Clocks并设置为自启动,可以自动控制Jetson的频率,点击Jetson Clocks处的inactivate和disable改为activate和enable:
打开前:
打开后:
VNC配置
VNC是一种Linux下远程桌面的互联协议,可以在远程查看Linux的桌面环境,这尤其在进行一些结果可视化,界面调试等工作的时候非常好用
但值得注意的是,由于Jetson开发板的设计缺陷或者默认Xorg服务的配置错误,Jetson必须在进入界面模式,连接显示器输出,并且显示器打开的情况下才能使用VNC访问桌面环境(还记得之前的关闭休眠吗?),其它情况下,就会黑屏或者只显示一个英伟达的图标,无法连接桌面
首先,需要在Jetson的命令行中安装VNC服务并默认启动VNC的服务:
1 | Gnome桌面 |
值得注意的是,默认服务可能有时无法启动,尤其是在长时间没有输密码进入桌面或者有网络问题时,很容易启动失败,需要手动确认5900端口是否打开
然后,需要配置VNC服务:
1 | gsettings set org.gnome.Vino prompt-enabled false # 有新连接时不需要得到弹窗提示的允许,方便远程连接 |
再设定连接VNC需要的密码,需要把其中的thepassword替换成你自己的密码:
1 | Replace thepassword with your desired password |
最后,重启之后可以使用客户端连上开发板
1 | sudo reboot |
值得注意的是,某些VNC客户端在连接Jetson时会出现异常卡顿的现象,这可能与JPEG压缩等有关,使用一些其它的客户端可能缓解问题,因此只建议使用VNC做调试
工具包配置
在Jetson上进行开发需要安装一些机器学习相关的软件和库,包括Miniconda,pytorch,ultralytics等等
安装Miniconda
Miniconda是一个好用的Python环境管理工具,可以把不同版本的Python工具进行隔离,方便进行管理
相对于Anaconda,其只去除了一些图形化的选项,只保留了核心工具,比较适合Jetson这种资源受限的平台
可以在https://www.anaconda.com/docs/getting-started/miniconda/install#aws-graviton2-arm-64找到详细的安装步骤,注意,由于Jetson使用arm架构的CPU,所以需要选择ARM64架构的安装包
安装成功后,重新进入终端,就可以看到conda的环境提示符:

conda的具体使用可以参考https://www.runoob.com/python-qt/anaconda-tutorial.html中conda命令一章
由于conda的源在国内访问不稳定,可以将conda和pip的源更换为国内源,具体步骤可以参考清华源的指引:
https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/
https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
对于环境的创建,推荐使用Python3.10进行
1 | conda create -n general_torch27_py310_cu126 python=3.10 |
激活环境:
1 | conda activate general_torch27_py310_cu126 |

安装pytorch
由于Jetson的硬件结构(arm64)和访存结构(CPU和GPU共用显存)与传统的工作站和服务器不同,Jetson需要特定的CUDA和Pytorch,CUDA在前文Jetson系统烧写的时候已经安装,与系统版本绑定,例如Jetpack 6.2版本使用的CUDA就是12.6版本
推荐使用CUDA 12.6版本对应的Pytorch,否则可能会在需要实时编译的库中遇到问题
而对于Pytorch,也需要安装针对于Jetson的特定版本,具体安装文档可以查询:
6.0之后:https://docs.nvidia.com/deeplearning/frameworks/install-pytorch-jetson-platform/index.html
6.0以前:https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
根据文档中的规格表和Jetpack版本表可以知道,对于6.2版本,可以安装2.7.0a0+79aa17489c版本的pytorch,具体如下:
安装libopenblas-dev(已经在烧写时安装)
安装cusparselt
安装pytorch包
值得注意的是,针对于Jetpack 6.2的pytorch包已经发出,可参见https://pypi.jetson-ai-lab.dev/jp6/cu126,但官方手册还未同步
1
2
3
4
5
6
7
8
9下载包
wget https://pypi.jetson-ai-lab.dev/jp6/cu126/+f/6ef/f643c0a7acda9/torch-2.7.0-cp310-cp310-linux_aarch64.whl#sha256=6eff643c0a7acda92734cc798338f733ff35c7df1a4434576f5ff7c66fc97319
安装numpy,注意,numpy更新了2的大版本,会导致很多库现在不支持
pip install 'numpy<2'
安装pytorch
export TORCH_INSTALL=./torch-2.7.0-cp310-cp310-linux_aarch64.whl
pip install --no-cache $TORCH_INSTALL可以使用如下代码验证安装:
1
2
3import torch
print(torch.cuda.is_available())
print(torch.backends.cudnn.is_available())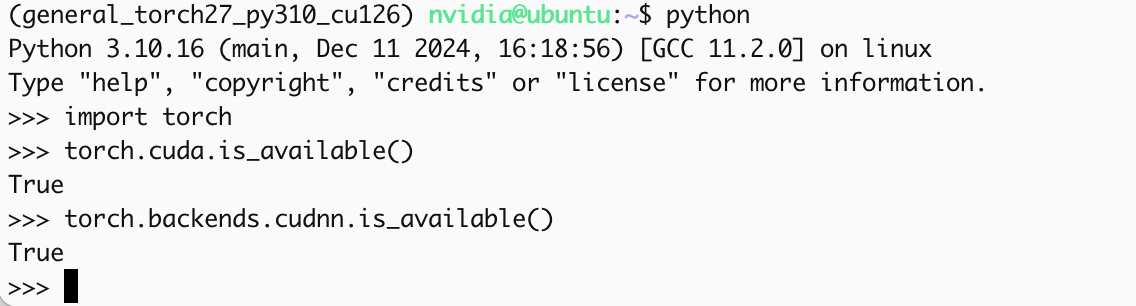
安装torchvisiontorchvision是专注于图像处理的torch相关库,提供了视觉处理相关的数据处理,预训练模型等1
pip3 install torchvision --index-url https://pypi.jetson-ai-lab.dev/jp6/cu126/
编译并安装torchvision
由于nvidia官方在编译torchvision的包时,并没有加入对于
torchvision::nms的CUDA支持,所以在使用yolo进行目标检测时是会报错的,有两种选择:- 针对目标检测重新创建环境,安装属于Jetpack6.1的torch和torchvision,实测可以通过https://forums.developer.nvidia.com/t/yolo-incompatible-with-jetpack-6-2-jetson-orin-nano-super/321078
- 重新编译torchvision(需要修改编译选项),可以参考https://forums.developer.nvidia.com/t/pytorch-for-jetson/72048
安装ultralytics
ultralytics集成了YOLO系列的众多模型,包括常用的YOLOv8系列,YOLOv11系列,并且对于端侧部署做了优化,是最常用的单阶段目标检测模型库,其也在最近支持了Orin系列,可以参考其官方文档1,官方文档2
首先需要安装一些依赖,自动搜索这些依赖会达到搜索最大深度,无法完成搜索和安装:
1 | 下载这些包,可以从https://pypi.jetson-ai-lab.dev/jp6/cu126找到 |
然后就可以直接使用命令安装,此处的export包含了对于onnx,torchscript等移动端模型的优化支持
1 | pip install ultralytics[export] |
一些库需要现场编译,所以可能会很慢
值得注意的是,由于一些库的依赖过深,会导致达到搜索上限,可以先安装基础的ultralytics,然后运行如下命令让ultralytics自动安装onnx组件,其它组件也是类似
2
3
自动安装onnx组件
yolo export model=yolo11n.pt format=onnx但对于tensorrt组件,需要GPU支持,同时需要onnxruntime-gpu,而上方只会安装onnxruntime,需要手动安装gpu版本
2
pip install onnxruntime_gpu-1.22.0-cp310-cp310-linux_aarch64.whl在安装tensorrt时,由于官方源中没有针对Jetson的tensorrt,需要在https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/10.3.0/tars/TensorRT-10.3.0.26.l4t.aarch64-gnu.cuda-12.6.tar.gz下载tar包之后,解压后找到其中的python文件夹中的包进行安装
2
3
pip install ./tensorrt_dispatch-10.3.0-cp310-none-linux_aarch64.whl
pip install ./tensorrt-10.3.0-cp310-none-linux_aarch64.whl
安装mmcv和mmdet(废弃,暂时无法使用)
mmcv系列是商汤开源的一系列深度学习工具,其中,mmdet和mmrotate是专注于目标检测的部分,其中包含了许多二阶段目标检测网络,其使用可以参考mmcv官方文档和mmdet官方文档
对于其安装,可以按照以下命令:
1 | pip install -U openmim |
安装带有CUDA加速的opencv
在Jetpack中,默认包含了opencv的库,但是,其默认不支持CUDA加速
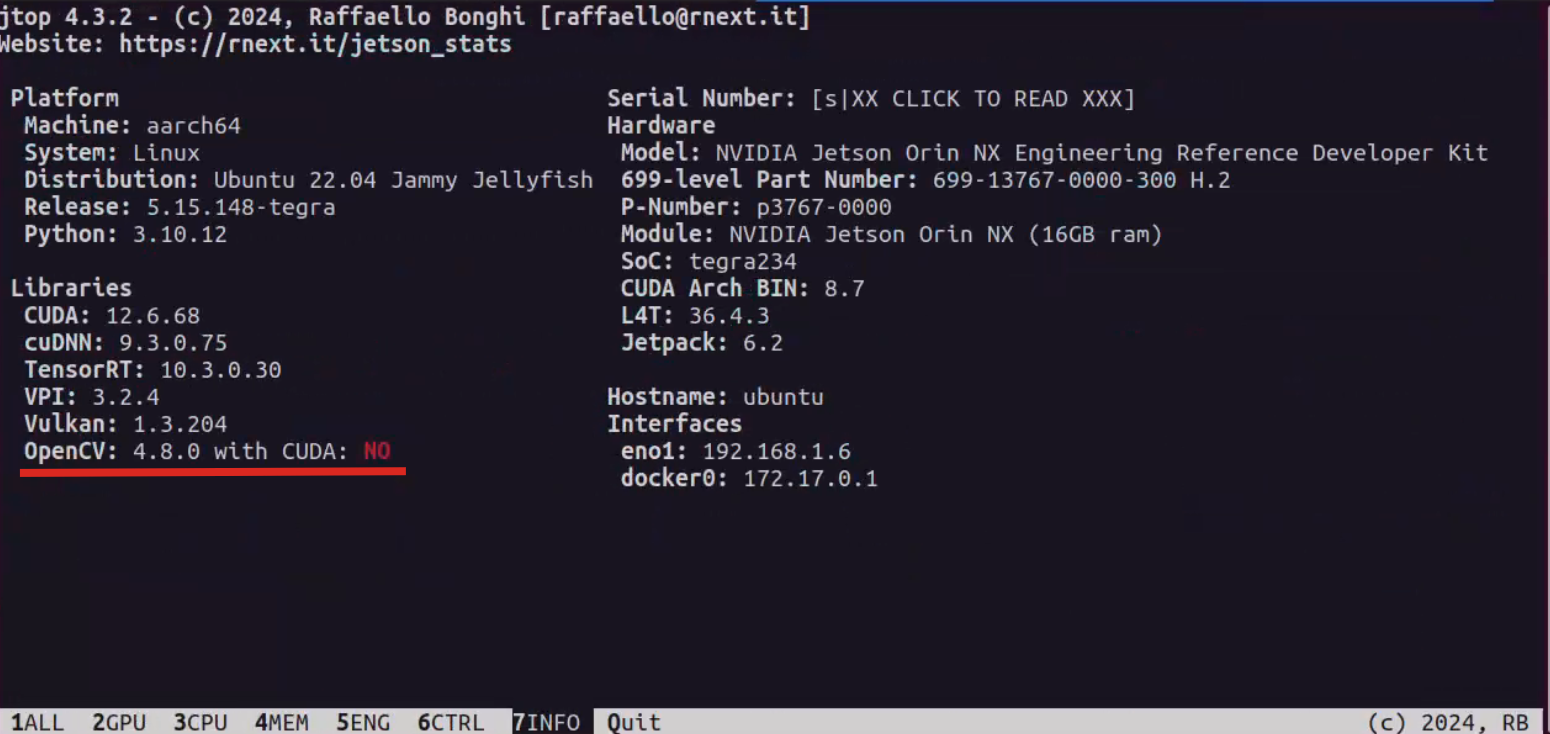
在图像处理中,Jetson较弱的CPU会带来较长的处理时间,好在opencv可以支持CUDA加速,可以使用第三方的脚本进行安装:
1 | wget https://raw.githubusercontent.com/Qengineering/Install-OpenCV-Jetson-Nano/refs/heads/main/OpenCV-4-10-0.sh |
注意可能遇到网络问题
在安装之后,可以看到jtop界面也发生了变化:
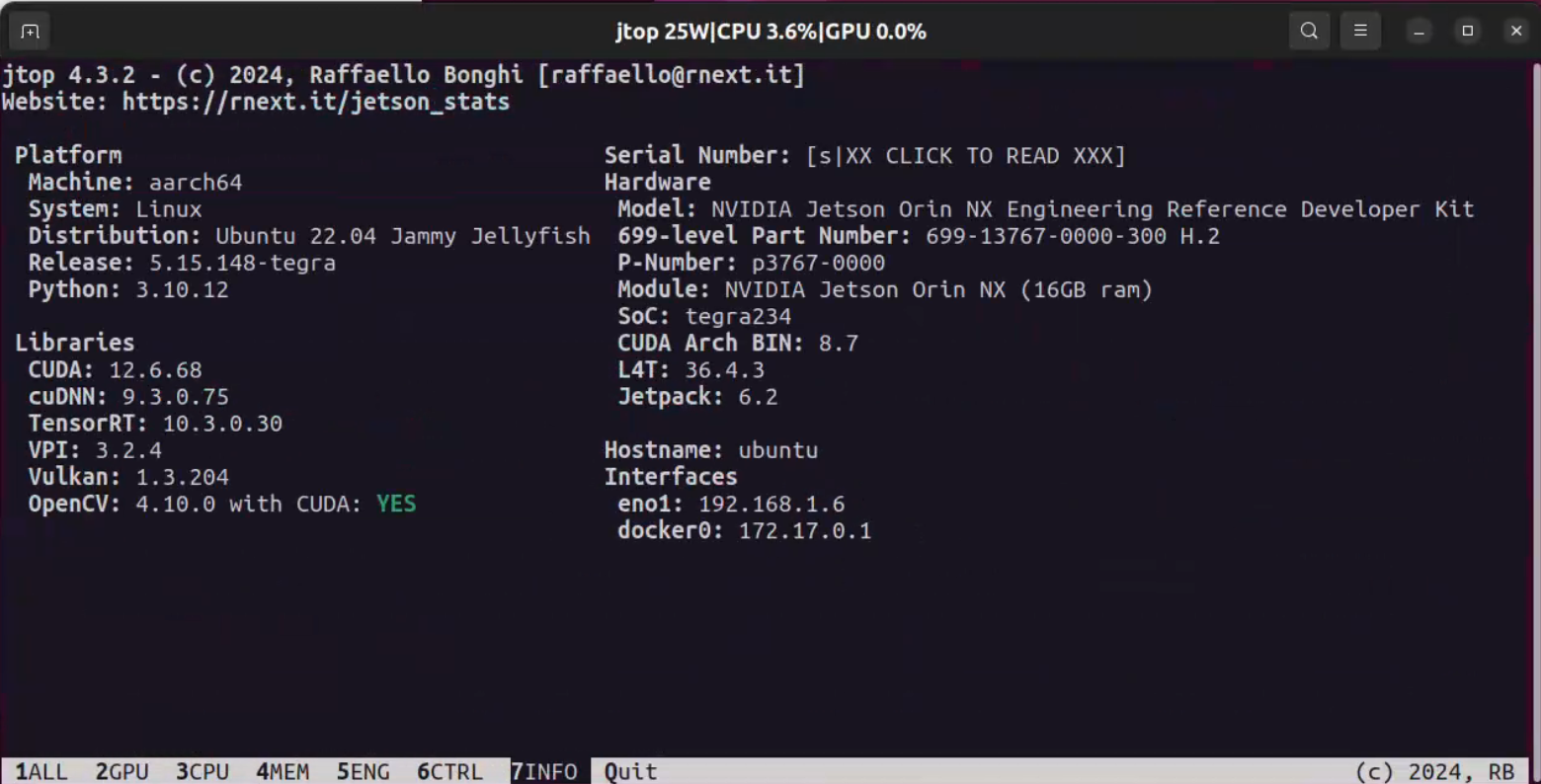
opencv中支持cuda的操作可以在cv2.cuda中进行调用
1 | import cv2 |
注意先运行
echo 'export OPENBLAS_CORETYPE=ARMV8' >> ~/.bashrc并重启终端来指示架构
安装相机pyorbbec SDK
对于Gemini 2相机,可以安装pyorbbec sdk来进行控制
安装前需要安装一些依赖:
1 | sudo apt install build-essential # cmake |
安装首先需要克隆官方代码并切换到v2版本:
1 | git clone https://github.com/orbbec/pyorbbecsdk.git |
然后由于是使用了conda,需要在CmakeList.txt中修改python路径,可以使用nano进行:
1 | sudo apt install nano |
在35行的find_package(Python3 REQUIRED COMPONENTS Interpreter Development)之前加入:
1 | set(Python3_ROOT_DIR "") # 需要在引号中填入环境的路径 |
接下来需要安装依赖环境:
1 | pip install -r requirements.txt |
注意,gcc的版本可能会对其中的udev的编译造成影响
进行编译:
1 | mkdir build |
这一步之后需要重启终端加载环境变量
安装为python包:
1 | cd .. |
值得注意的是,由于需要与硬件进行交互,需要设置udev规则来进行允许:
1 | sudo bash ./scripts/install_udev_rules.sh |
然后摄像机就可以正常工作了,例如,可以调用官方的示例:
1 | python3 examples/depth_viewer.py |
需要注意的是,这需要显示画面,即Jetson需要有视频输出
平台使用入门
相机调用(pyorbbec SDK使用)
对于Gemini 2相机的调用,有两种形式:
- 利用通用接口,即Linux的设备管理和图像处理库(一般是opencv),具体可以参考教程
- 利用相机提供的SDK进行控制,例如,Gemini 2提供了c++,python等语言的SDK支持,pyorbbec SDK就是针对于Python的SDK,提供了相机初始化,曝光控制,传感器控制等选项
有关于Python的教程可以查看https://www.runoob.com/python3/python3-tutorial.html
pyorbbec SDK概念
在pyorbbec SDK中,为了更方便操作设备,会分为几个层级,按照流程进行操作,从最接近底层到应用层分别为:
官方文档https://orbbec.github.io/OrbbecSDK/doc/tutorial/English/OverviewDocument.html
Context:整个处理上下文,提供了一组设置,包括设备访问,状态变化回调,日志等
一般来说,由于Context过于底层,不建议使用Context操控设备,在创建pipeline时,会自动隐含创建一个Context
Device:设备对象,一个实际的硬件设备对应一个Device对象,例如一个Gemini 2,该对象用于获取设备的相关信息,并控制设备的属性(传感器等)
同样,也不建议使用Device操作设备进行应用编写
Sensor:传感器对象,可以理解为实际设备的子设备,例如RGB传感器,深度传感器等,一个Device可能包含多个Device
同样,也不建议使用Sensor操作设备进行应用编写
Pipeline:流程对象,对底层结构进行了封装,包含了可以快速访问的结构,功能简洁,方便进行开发
Config:整体控制对象,包含了对于整个设备和流程的控制,例如光学传感器的分辨率,刷新率
Profile:设备和流程控制对象,具体控制流程中的参数,例如,VideoStreamProfile控制拍摄视频的分辨率,刷新率等等
Frame:视频中的一帧数据,同时包含该帧数据的相关信息,比如时间戳,图像元数据,类型等
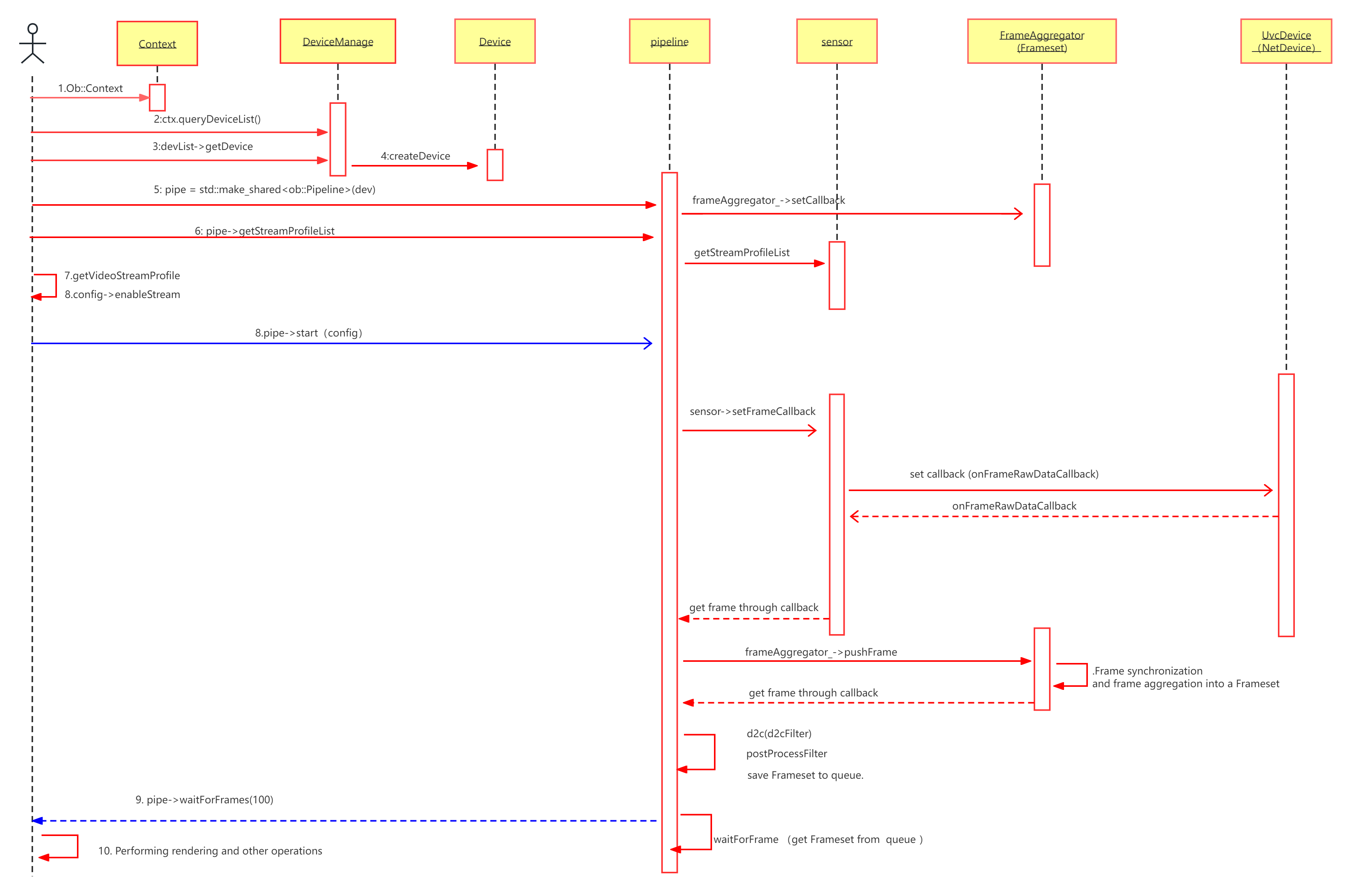
获取设备信息
即示例1.get_device_info.py
设备级别的控制和访问需要Context进行,需要通过创建Context访问Device,进而访问设备信息
1 | ... |
访问内参
相机的内参即焦距(fx, fy)、主点坐标(cx, cy)、畸变参数,可以把坐标从相机坐标系转换到像素坐标系中,与相机本身绑定,可以通过两种方式获取内参,即Pipeline和Profile
但值得注意的是,相机内参需要确定分辨率等信息,Pipeline获取的是图像参数与相机内参的对应列表,Profile获取的是这种配置情况下的内参
1 | pipeline = Pipeline() |
时钟同步
如果需要自主控制成像(固定时间,RGB-D对齐。。),需要在代码中进行精确时钟同步:
如果硬件自动同步就不需要
1 | from pyorbbecsdk import * |
开启相机
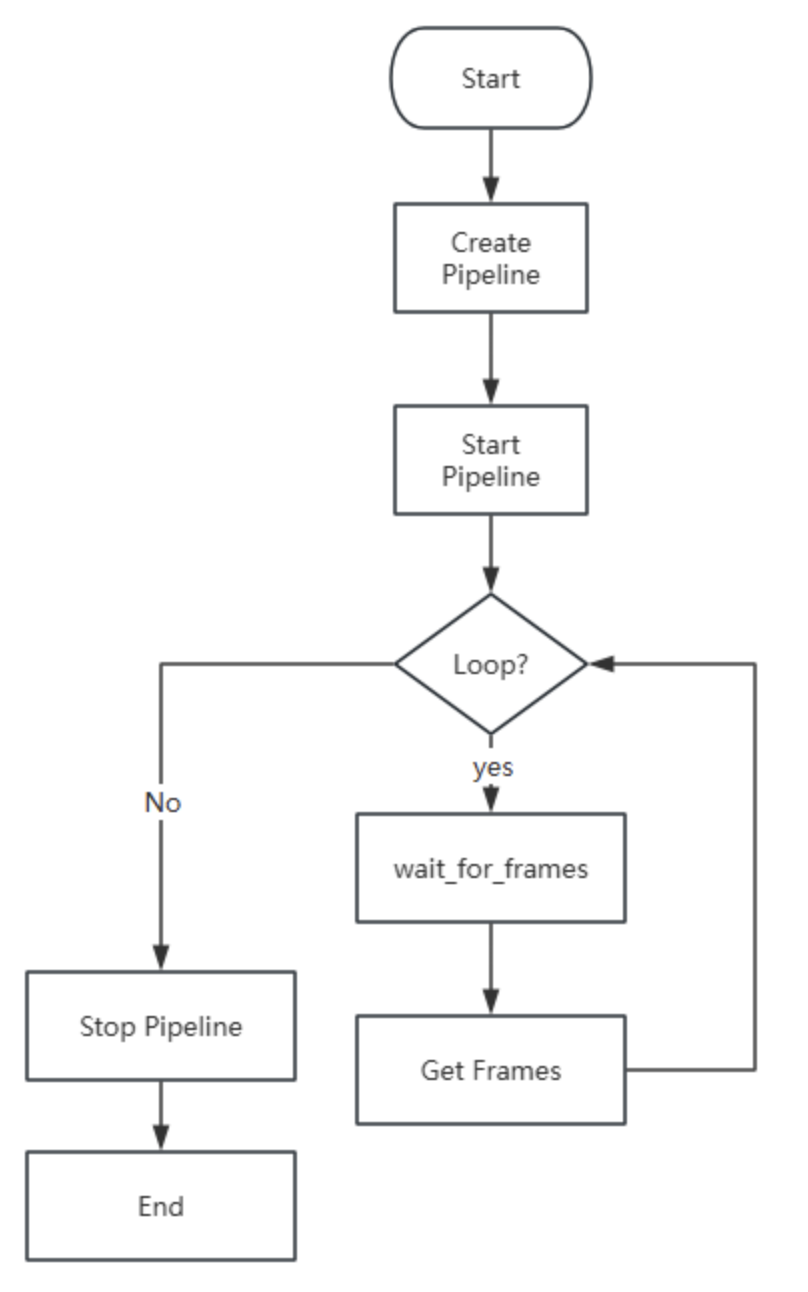
我们使用一个简单的示例来展示如何进行相机控制,控制有两种方式,一种是主动式,一种是使用回调
主动控制:
首先需要引入pyorbbec包,在其中,对底层的c++进行了封装,
1 | from pyorbbecsdk import * |
然后,需要创建pipeline,来控制整个流程,并对参数进行配置:
1 | pipeline = Pipeline() |
接下来配置相机信息:
1 | profile_list = pipeline.get_stream_profile_list(OBSensorType.COLOR_SENSOR) |
开始工作:
1 | config.enable_stream(color_profile) |
对每一帧进行处理:
1 | while True: |
中断和回调函数
对于相机这种外围设备,其速度与CPU有差异(RGB相机获取图像很慢,imu等频率很高),由此,如果使用循环一直等待然后进行处理,CPU必定需要进行等待,导致当前进程一直停滞,一种解决方法就是利用中断机制,使用回调函数进行处理
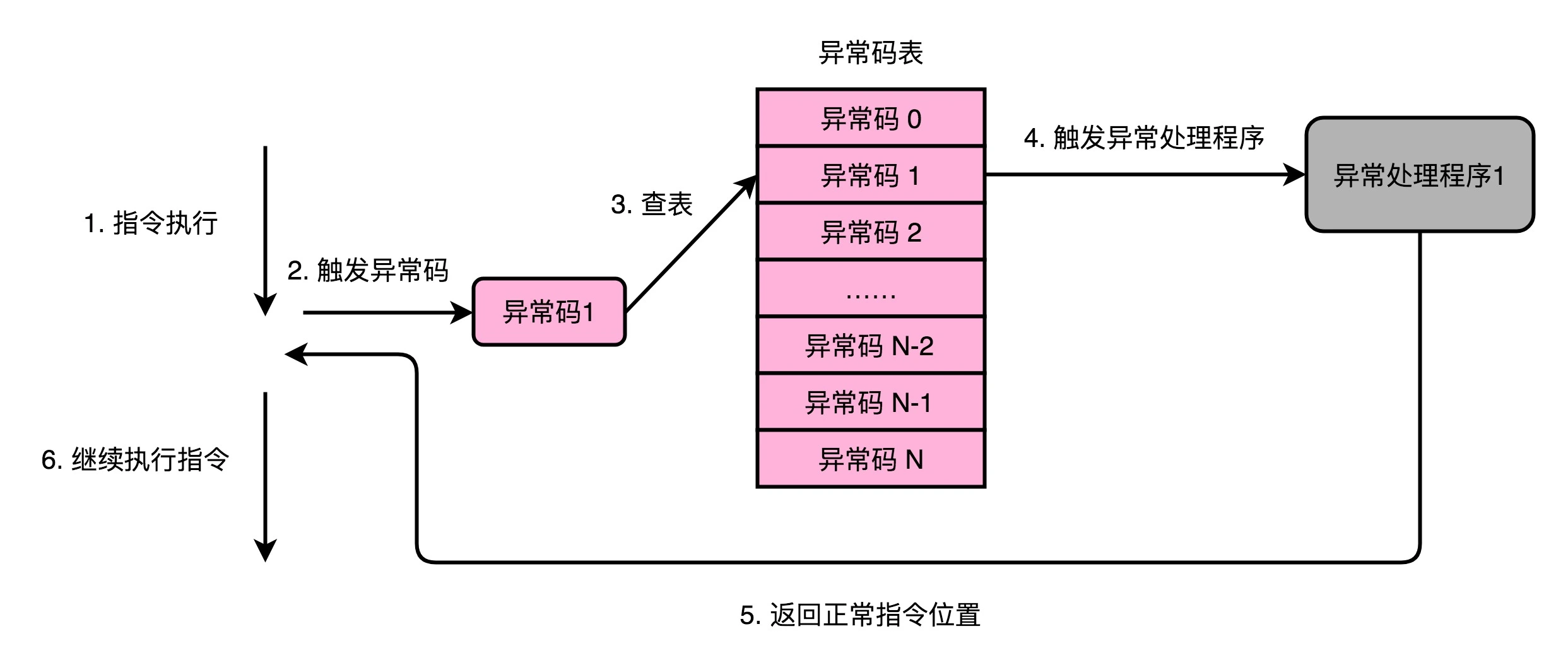
如上图中,CPU可以继续执行其它指令,在收到中断(图像完成等),执行回调函数(预先写好的处理程序),然后继续执行指令
中断的核心在于回调函数的书写:
1 | def get_color_depth_frame_callback(data_queue: AlignedQueue): |
然后只需要在开始执行之后,把回调函数注册到进程中,在中断时就会自动执行回调函数:
1 | pipeline.start(self.config, call_back) |
硬件同步
可以看到,在多个传感器或设备同时工作时,其获得的时间戳可能是不相同的,由此,在这样的场景中,就需要对传感器进行同步,同步分为硬件同步和软件同步:
- 软件同步:软件同步故名思义,就是利用软件进行判断,通过时间戳,网络命令等协调多个传感器之间的采集
- 硬件同步:利用相机本身的硬件,例如内置时钟信号连接,协调多个 传感器之间的采集
一般来说,由于软件同步会造成一定的CPU占用,如果有硬件同步支持,优先使用硬件同步
Gemini 2带有硬件同步的支持,需要手动进行开启,在Config中,有一个额外的get_d2c_depth_profile_list进行设置:
1 | ... |
图像处理入门
opencv使用
opencv是一个图像处理库,其中包含了许多图像处理的方法,主要用于图像加载,预处理,后处理等,也包含许多传统机器学习方法,是图像处理的综合性库,具体使用可以参见https://codec.wang/docs/opencv,https://docs.opencv.org/4.x/index.html等文档
这里列出了一些典型的图像操作:
1 | import cv2 |
包括对于视频的操作:
1 | import numpy as np |
保存视频相对麻烦,因为要根据所有视频帧进行编码为一个文件,需要使用
VideoWriter对象实现
实际上,opencv中更加复杂的是各种图像/视频处理:
例如:
变换类:几何变换,边缘滤波,图像分割。。。

特征检测类:角点检测,特征追踪,特征匹配。。。

机器学习类:K近邻,SVM。。。
另一方面,在前文进行安装之后,其中的cuda模块也是重要的一环,我们知道,Jetson的CPU实际上相对较弱,而GPU性能较强,所以可以通过GPU进行加速,一般GPU处理涉及到三个步骤:
在GPU的空间内申请空间,把图像上传到GPU显存
1
2
3# Upload the image to the GPU
gpu_image = cv2.cuda_GpuMat()
gpu_image.upload(image)尽管JetsonCPU和GPU物理上共用显存,但似乎为了符合现代计算机结构,在逻辑上还是分了内存和显存,至少opencv还是需要执行相应步骤
在GPU上进行图像处理
将图像下载到内存
1
2# Download the result back to the CPU
result_image = gpu_blurred_image.download()
由于实际上多出来上传和下载的步骤,小批量图像的简单的操作,例如单张图像施加高斯噪声等,在GPU上会更慢,最适合在GPU上处理的是大批量,高复杂度,并行化的任务
参见代码opencv 1和2
yolo系列检测模型使用
对于Jetson这样的设别来说,一类比较适合的任务就是这样的实时视觉检测,ultralytics提供了YOLOv8和YOLOv11两个系列的模型,并提供了边缘计算的支持
对于很多模型来说,其都是在大型服务器上进行训练,机器的吞吐量,读写等方面与端侧不同,对端侧的推理优化是部署的很重要的方面
其边缘计算的能力主要由在Jetson上主要使用TensorRT进行加速,幸运的是,YOLO系列模型封装了相关的函数,可以利用export将标准的YOLO模型转换为TensorRT模型:
可以查询到其参数https://docs.ultralytics.com/integrations/tensorrt/#export-arguments
1 | from ultralytics import YOLO |
tensorrt需要对于其中的计算步骤进行自动优化(),会进行层融合,精度校准,动态内存管理等,由此,输入的图像尺寸会固定
已知Jetpack 6.2的torch 2.7.0 和torchvision 0.22.0的编译存在问题,与ultralytics不兼容


可以看到,使用tensorrt优化之后的模型在推理速度上会有较大的提升
在后处理部分,nms大部分还是使用cpu进行
另一方面的选择其实是是否量化,一般在训练时,会采用Float32精度进行,混合训练也只会用到float16,但在推理时,可以使用INT8等更小的类型进行,这也可以使用tensorrt进行实现,只需要在export中进行设定:
1 | from ultralytics import YOLO |
同时,在export出int8时最好指定一个data的数据集,来确定模型的适用范围

这样会有两方面的影响:
- 优点:速度快,模型存储占用小,对于资源受限平台友好
- 缺点:可能减少泛化性,甚至降低性能

为了进一步降低功耗,部分网络层可以跑在Jetson专属的深度学习加速器上,但可能带来一定的性能下降,同样,也是在export时进行选择,使用device选项:
1 | from ultralytics import YOLO |
对于视频处理,可以使用deepstream,参考https://docs.ultralytics.com/zh/guides/deepstream-nvidia-jetson/#deepstream-configuration-for-yolo11
可用资源汇总
Jetson官方初始文档:https://developer.nvidia.cn/embedded/learn/getting-started-jetson
Jetson官方文档集:https://docs.nvidia.com/jetson/
英伟达论坛Jetson专区:https://forums.developer.nvidia.com/c/robotics-edge-computing/jetson-embedded-systems/70
专属于Jetpack 6的最新包:https://pypi.jetson-ai-lab.dev/jp6/cu126
奥比中光官方Github:https://github.com/orbbec