[论文笔记] dove
信息
Title: Images are Worth Variable Length of Representations
Author: Lingjun Mao, Rodolfo Corona, Xin Liang, Wenhao Yan, Zineng Tang
Year: 2025
Publish: arxiv
Organization: University of California, University of Washington
Code: https://github.com/mao1207/DOVE/tree/main
Keyword: 视觉表征
背景
现代网络(Transformer)都是基于离散化token序列来表征信息,可以分为两类:
- 语义特征学习:CLIP,DINO
- 基于自动编码器的图像序列化:VAE,MAE

其都生成固定长度的token,但不同图像的信息密度不同,固定长度的token不一定合适
文本使用subword tokenization algorithms,一定程度上解决了信息密度不一致问题
这篇文章建立在用token的长度控制图像语义特征的想法上,同时,联想人类视觉关注主体的特性
相对于NLP的分词,这更像是一种图像自动tokenizer技术,不是
- 纯粹基于底层像素的
- 针对上层语义的(物体主体的图像,描述整张图片的简短文字。。。)
但
- 导致tokenizer部分过大,设计复杂,不利于scaling
- 没有考虑到图像的信息密度的不同层级
贡献点:
- 提出了DOVE,一个视觉编码器,根据图像复杂度生成可变长度的token
- 提出了DOVE的一种变体,可以使用text作为query找出对应的主题特征,由此更加减少token长度
- 实验发现了模型特征空间中表达的语义,并且性能超过其它基于AE的方法
方法
DOVE
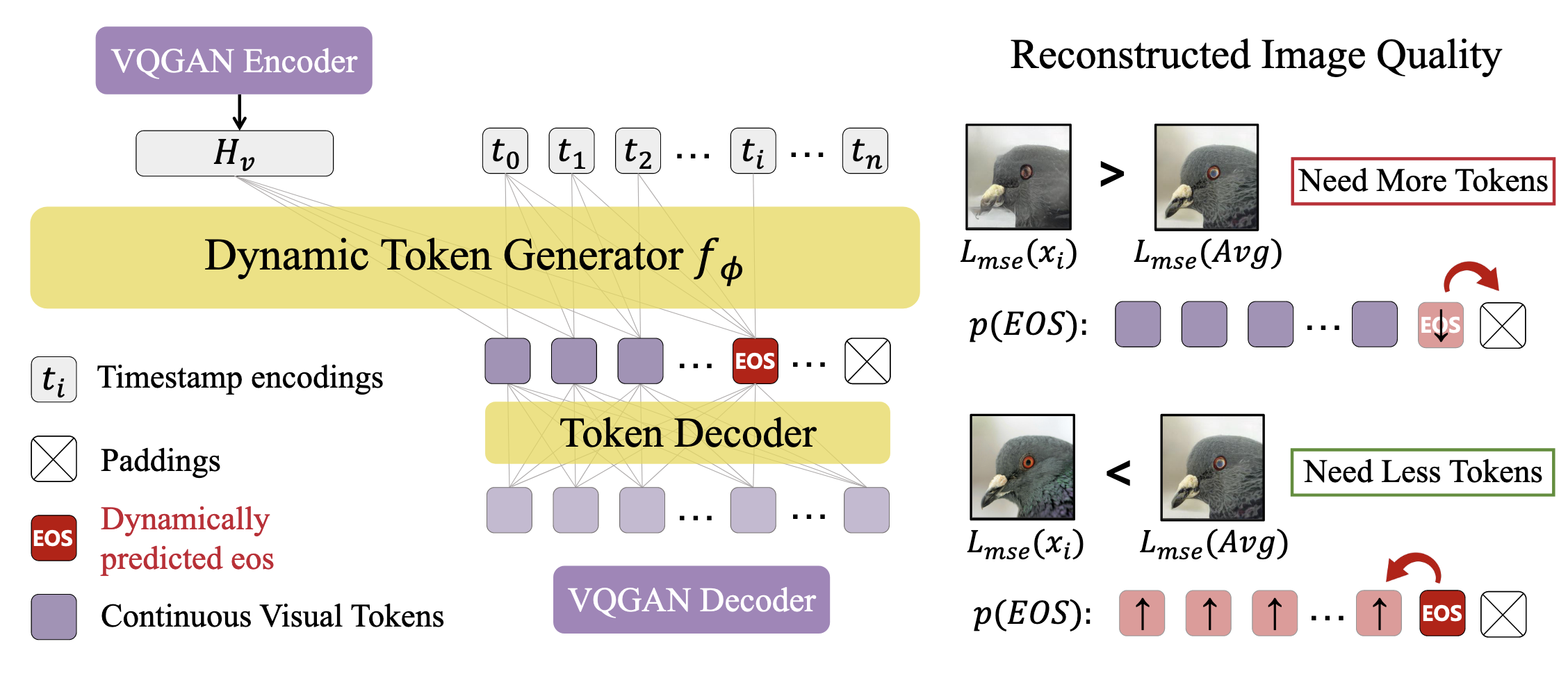
在VQGAN上进行改动,在VQGAN encoder和decoder之间套了一层encoder-decoder结构,用于生成EOS标志,generator和token decoder各使用了一个70M的因果transformer和双向transformer
使用VQGAN的encoder获取图像特征 ,同时利用周期信号生成时间步embedding ~,送入token生成器,利用因果attention进行生成:
在生成EOS token后,会将所有之后的token全部置零
然后使用一个双向注意力的decoder来将token序列映射到原长度,相当于encoder-decoder做了一次token映射/信息压缩/筛选
对于图像重建质量,采用了
- MSE损失和一个视觉感知损失控制图像重建
- 一个轻量化对抗损失来控制重建图像的现实性
训练中,为了避免幻觉,,
而对于EOS的生成,使用另一个损失作为一个正则项(理解):
使用过去100个step的平均重建损失作为动态阈值,如果损失小于阈值,EOS应该更靠前,大于阈值,EOS更靠后
使用代表预测的在第i个位置为EOS的概率,m为当前的token位置,那么token长度控制损失就为:
最终损失为:
一开始为一个极小值,随步数增加而增大
Q-DOVE
在grounding设定下,提出了Q-DOVE,依赖于文字来缩放token长度
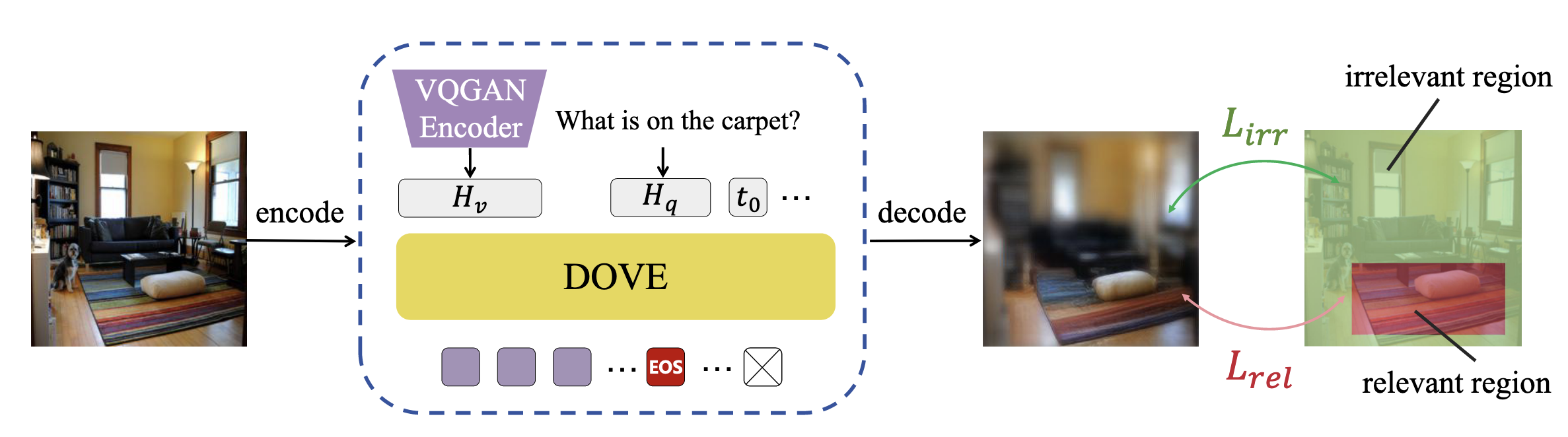
修改重建损失与目标框的相关度更高,同时计算目标框和目标框外的图像的重建损失:
最终损失取两者之和:
在文章中,设定为1e-10
而在此处,在计算的时候,对比的只是相关区域的损失均值
这种监督策略有两种好处:
- 让模型学习去看什么
- 要从图像中获取多少token
实验
设定
使用一个codebook为8192的VQGAN和轻量化的Pythia-70M语言模型
在ImageNet-1K上微调20epoch,两张4090,对于Q-DOVE,在Visual Genome and Open Images上再训练5epoch
- Visual Genome上使用给定的问题和区域描述作为文本输入,有给定的bbox
- Open Images没有区域描述或问题,使用关系标注构建text,并融合出现物体的bbox
掩码50%的文本作为数据增强,如果为null,就指定为整个图像
token级
使用FID分数衡量图像效果:
使用一个预训练的Inception v3模型衡量两个图像的分布差异,越小越好
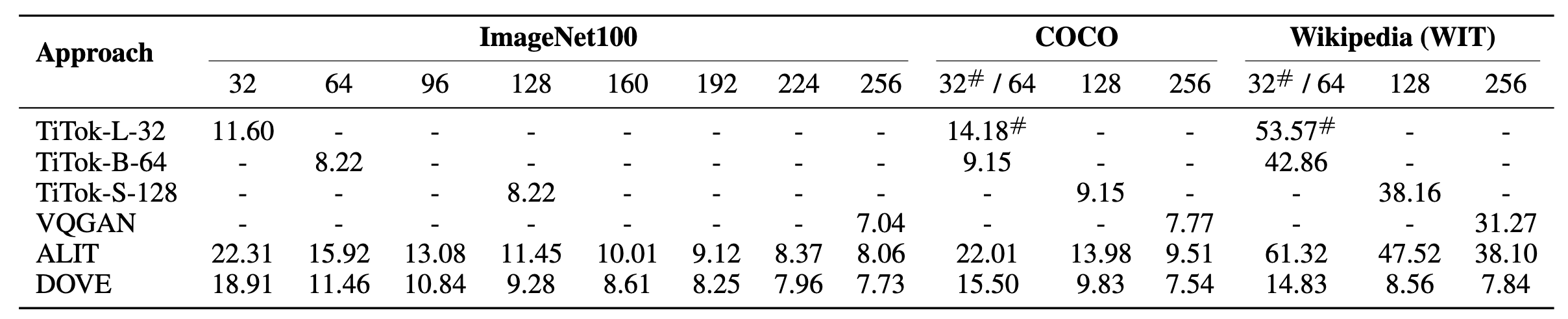
但结果似乎有些问题,很多时候比不上其它模型,可能是:
- FID分数问题
- DOVE更倾向于生成blur但包含更高级语义信息的图像,很多时候造成更好的分数
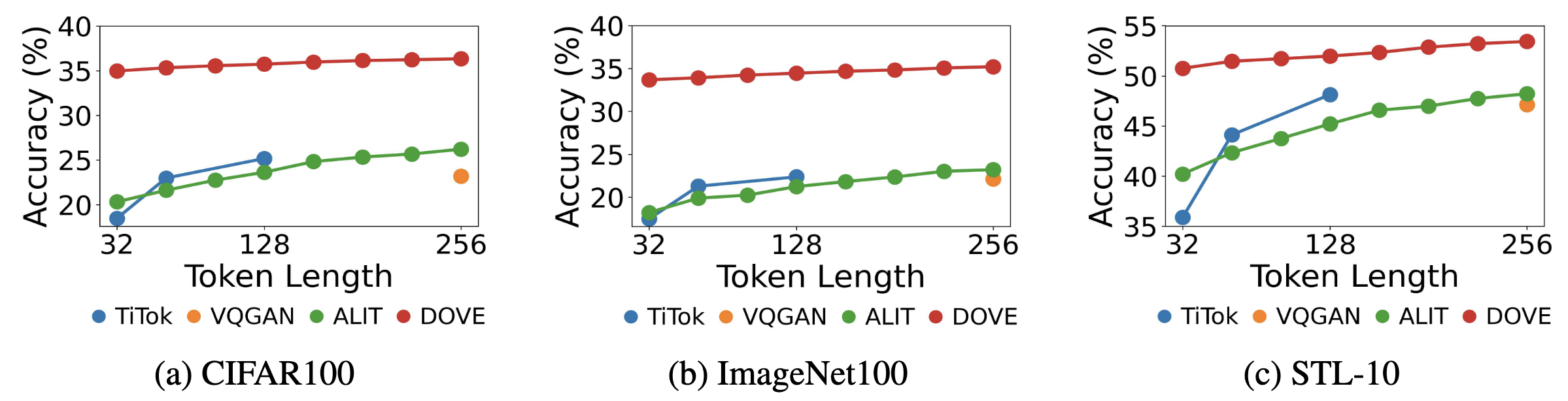
linear probing分类:
在整个数据集上,token长度分布:
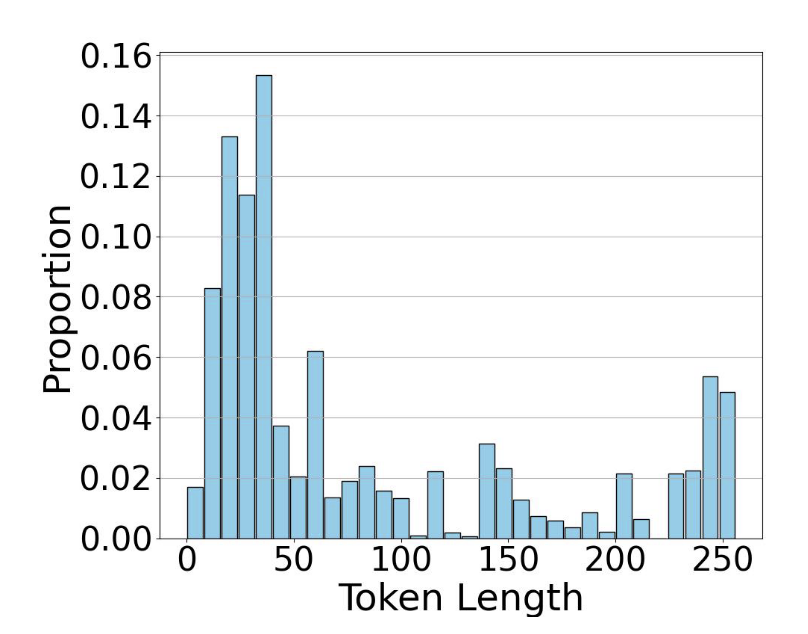
两头分布?需要再进行测试
同样,使用Laplacian variance计算了图像复杂度和平均token长度之间的关系:
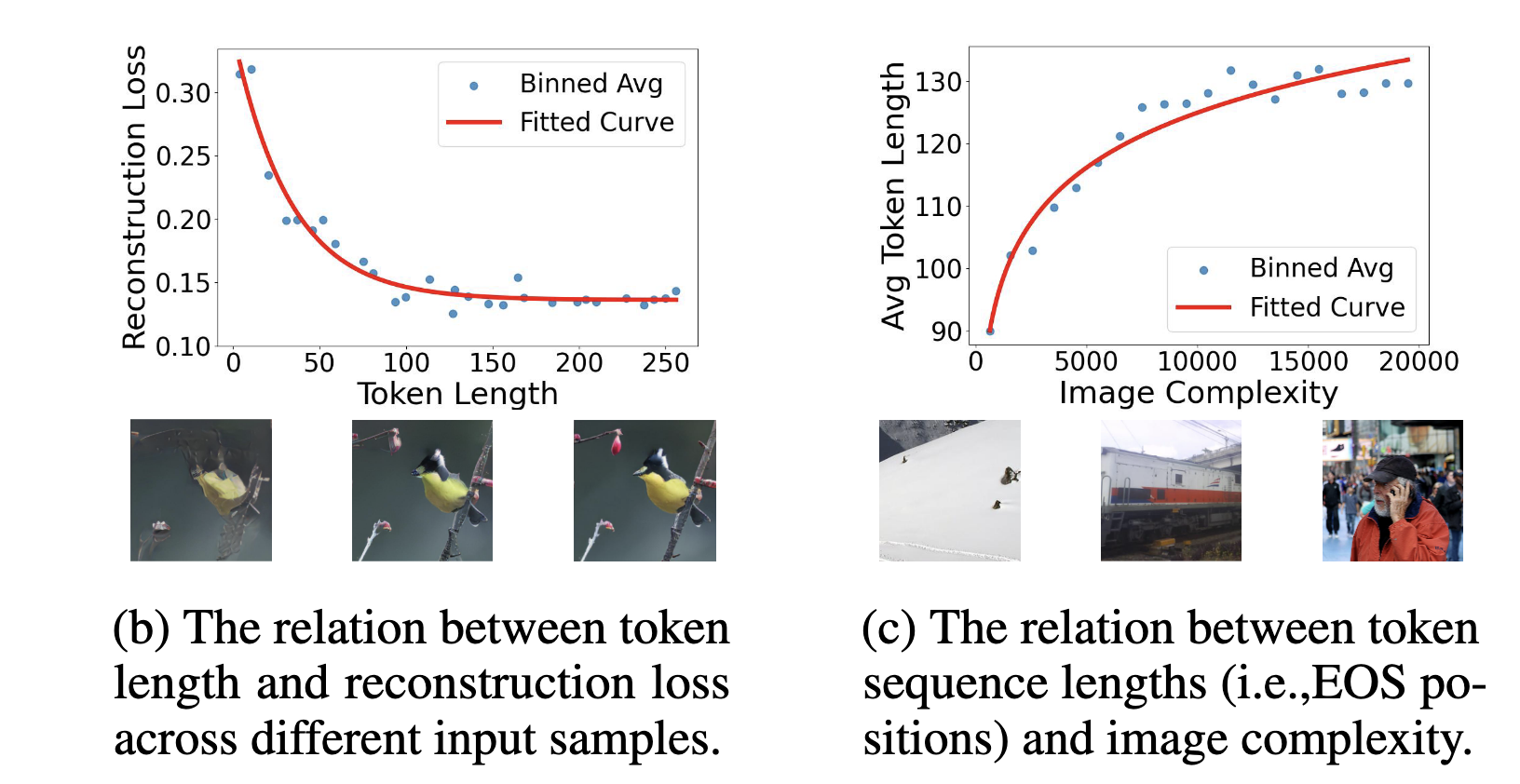
下游任务
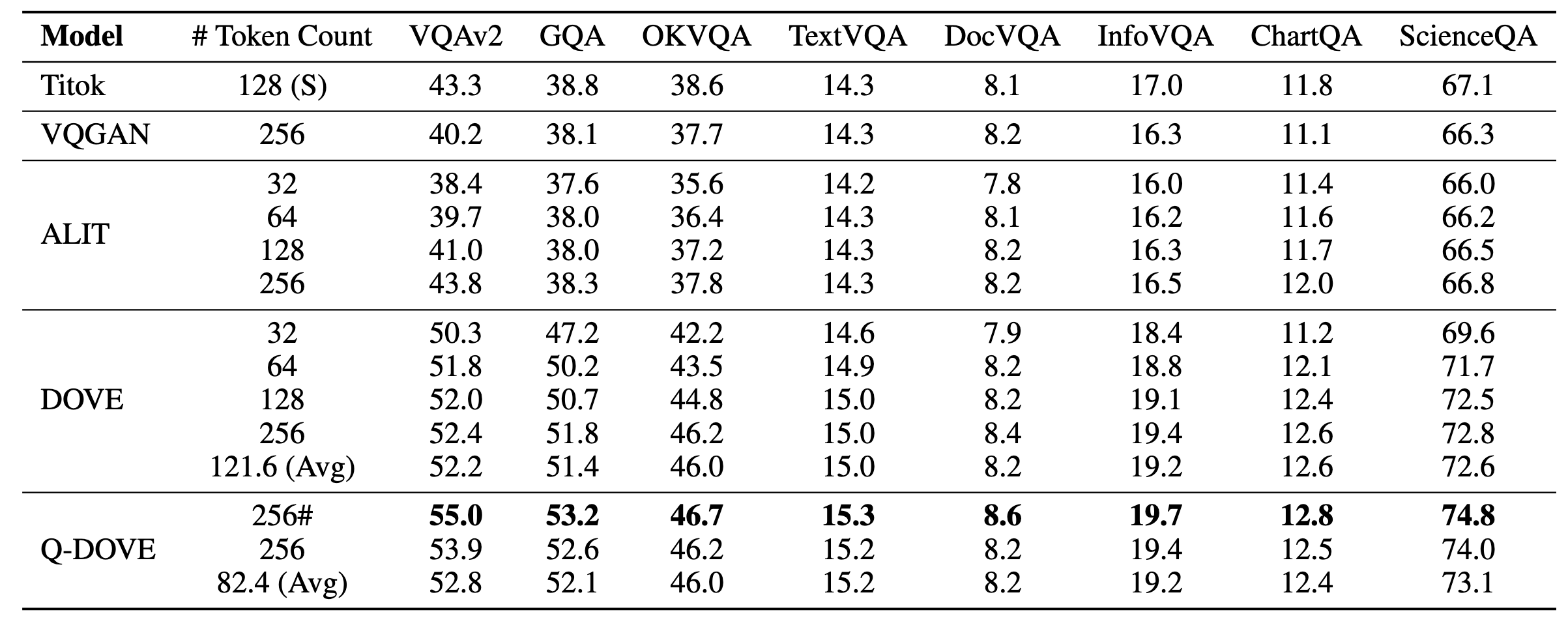
grounding的Q-DOVE:

在VQA上使用LLaVa,#表示输入的query为null
速度对比:

聚类分割
使用PCA可视化最终特征:

总结
自动可变长度token的结构,优点:
- 在语义表征方面有优势,有效剔除冗余信息
- 有Q-变种,结合语言信息
缺陷 :
- 实际上并没有提升效率,计算量反而增大了
- 更偏向于生成blur具有全局语义的特征,适用于分类,不适用于像素级任务