信息
Title: Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
Author: Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, Liwei Wang
Publish: NeurIPS
Year: 2024
Keyword: Autoregressive, self-supervised
Code: https://github.com/FoundationVision/VAR
关键词:自回归,Transformer,图像生成
背景
NLP中,LLM在泛化性和多样性上朝AGI更进一步,其核心在于自回归的自监督学习模型的可拓展性和泛化性(scaling law和零样本能力)
CV中,就尝试利用序列编码器将图像patch变为2Dtoken,并变为1D token做自回归,但拓展后性能不好,落后于扩散模型
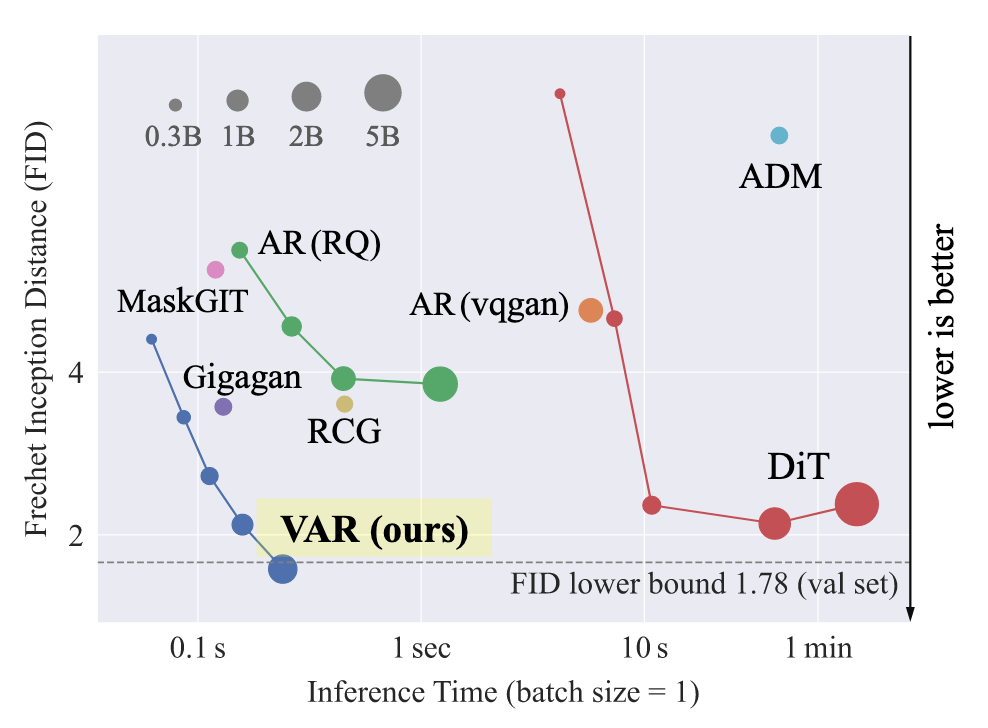
Frechet Inception distance是衡量生成模型生成质量的参数,衡量了整个数据集中生成图像和原始图像之间分布的距离(即一个数据集计算一个值)
计算中,首先两张图片先经过一个网络(一般为Inception v3),其符合高斯分布,然后对特征计算均值和方差,最终计算距离:
FID=∥μr−μg∥2+Tr(Σr+Σg−2(ΣrΣg)1/2)
值得注意的是,FID是针对于整个数据集的指标,而非像LPIPS一样针对单张图像
Inception Score (IS)用于衡量生成图像的质量,主要标准为现实性和多样性,使用Inception v3分类模型衡量,现实性体现在能生成能使模型准确分类的图像,多样从模型能生成一系列类的图像而非一部分类
视觉基础模型:CLIP,SAM,Dinov2,提示工程:Painter,LVM
Raster扫描自回归:VQVAE,VQGAN,VQVAE-2,RQ-Transformer,Parti
掩码预测:MaskGIT,MagViT,MUSE
扩散模型:DiT,U-ViT,Stable diffusion,SORA,Vidu
自回归要点在于数据的顺序,人类一般多层次接受,首先看整体结构,然后逐渐关注细节信息
作者将视觉的自回归定义为下一个尺度的预测,Visual Autoregressive modeling
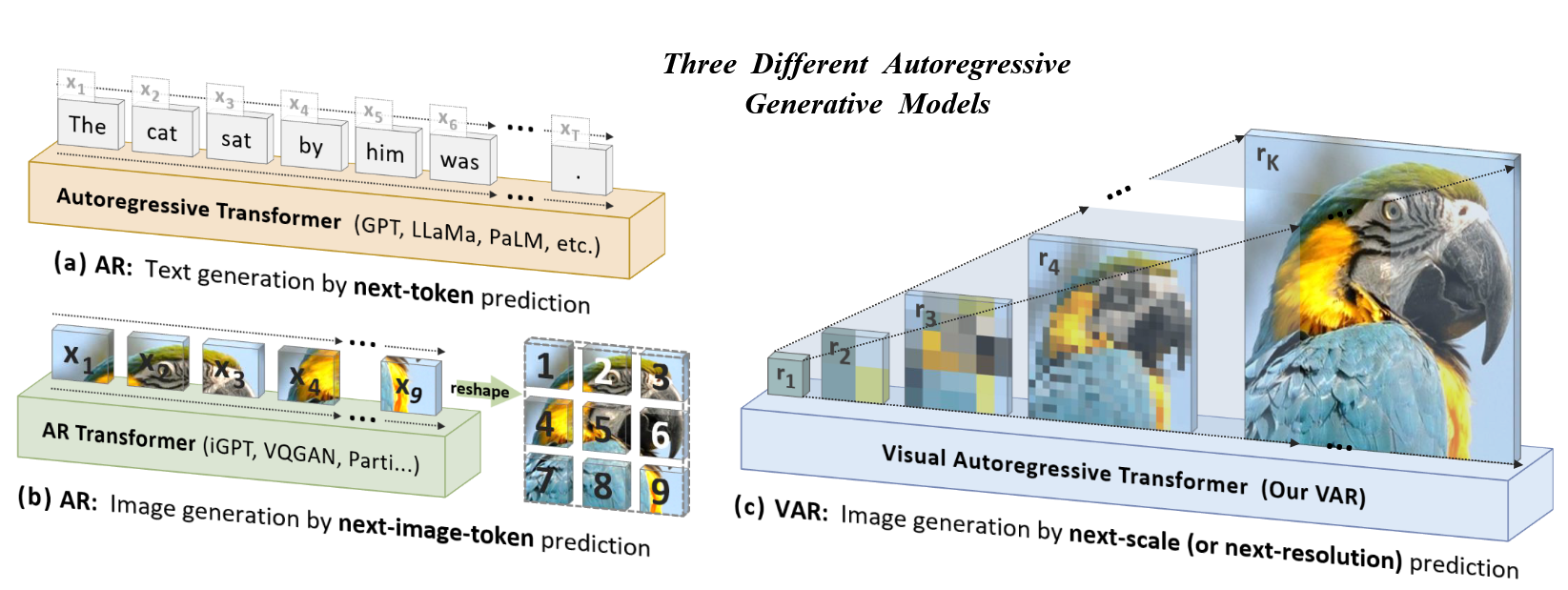
贡献:
- 提出了多尺度预测的自回归生成方式,由整体结构到细节信息进行预测
- 使用类似GPT-2的结构,实现多尺度视觉自回归
- 验证了模型的可拓展性和零样本能力
方法
前置信息:基于下个token预测的自回归
基于单项序列依赖的假设,序列x的可能性就可以因式分解:
p(x1,x2,…,xT)=t=1∏Tp(xt∣x1,x2,…,xt−1)
图像是2D连续信号,需要进行序列化,并决定顺序:
f=E(im),q=Q(f)
其中,im是原始图像,E(⋅)是编码器,Q(⋅)是序列化器,序列化器通常包含一个词典,会将特征向量映射到欧几里得空间中的编码序列:
q(i,j)=(v∈[V]argminlookup(Z,v)−f(i,j)2)∈[V]
由此,通过词书Z得到一个编号,并用decoder获取重建的图像,并计算损失:
f^=lookup(Z,q),im^=D(f^)L=∥im−im^∥2+∥f−f^∥2+λPLP(im^)+λGLG(im^)
其中,LP(⋅)是一个感性的损失,例如LPIPS,LG(⋅)是一个判别行损失
更像是encoder-映射-decoder来进行自回归
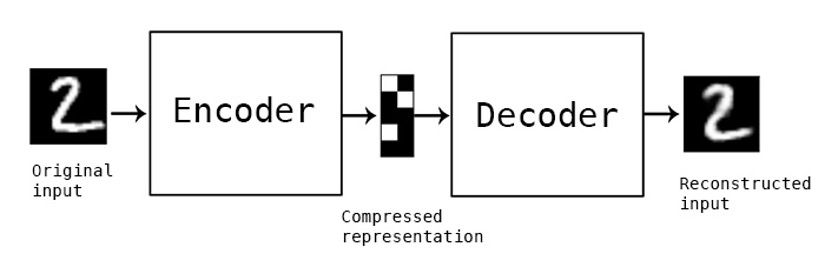
由此,自编码器{E,Q,D}就可以进行单向自回归
缺点:
假设违背:这样产生的所有特征f(i,j),相互之间存在依赖,flatten之后就会有双向依赖,但对于自回归,建立在应该只有单向依赖上
VQVAE的注意力分数图(1D token)
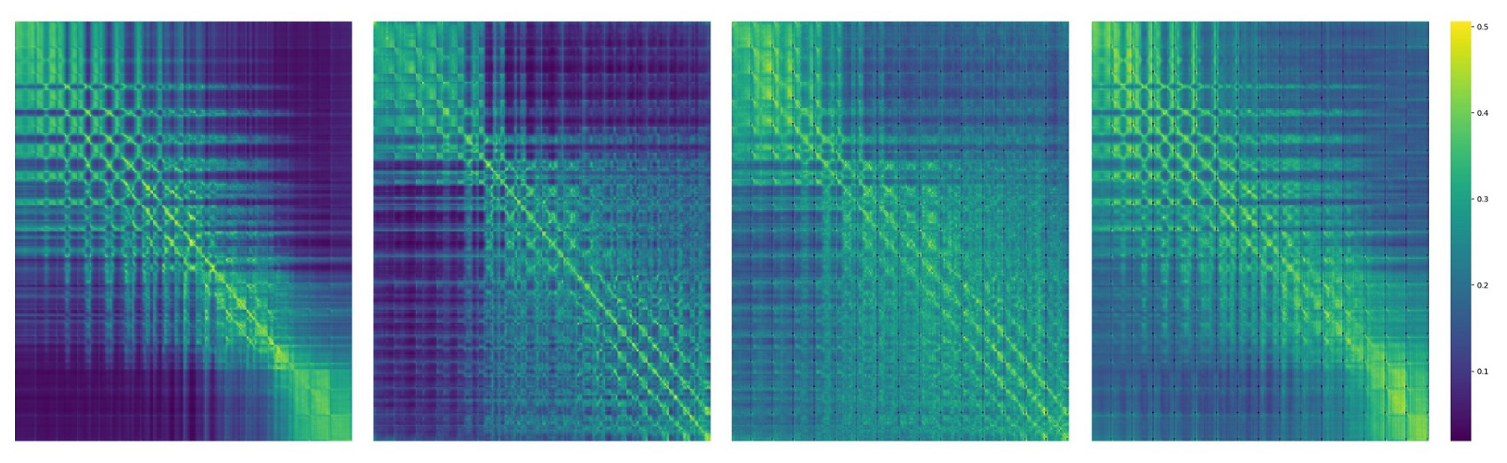
无法适用于下游任务:需要相互关系的下游任务无法应用

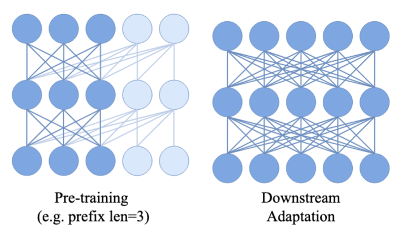
结构退化:图像空间结构也包含有信息
效率低:transformer是O(n2),加上自回归就是O(n6)
时间复杂度分析:
引理:对于标准的self-attention,对于AR的复杂度为O(n6),其中h=w=n
证明:
所有token的数量是n2
但值得注意的是,这是基于像素的回归,而不是基于patch的回归
由此需要回归n2次,而transformer的计算复杂度为O(i2)
由此可以求得总的时间复杂度为:
i=1∑n2i2=61n2(n2+1)(2n2+1)
即O(n6)
但需要注意:
1.此处是基于像素的回归,n代表像素数量,但在基于视觉的模型中较少使用,给出的对比方法中也是21,22年左右的方法
2.时间复杂度并不代表实际时间,只是时间随分辨率增长的趋势
基于下一尺度预测的视觉自回归
首先将一张图量化为K个多尺度的(r1,r2,…,rK),分辨率依次递增,那么自回归就变成了:
p(r1,r2,…,rK)=k=1∏Kp(rk∣r1,r2,…,rk−1)
使用了block因果mask来保证只看到之前的token:
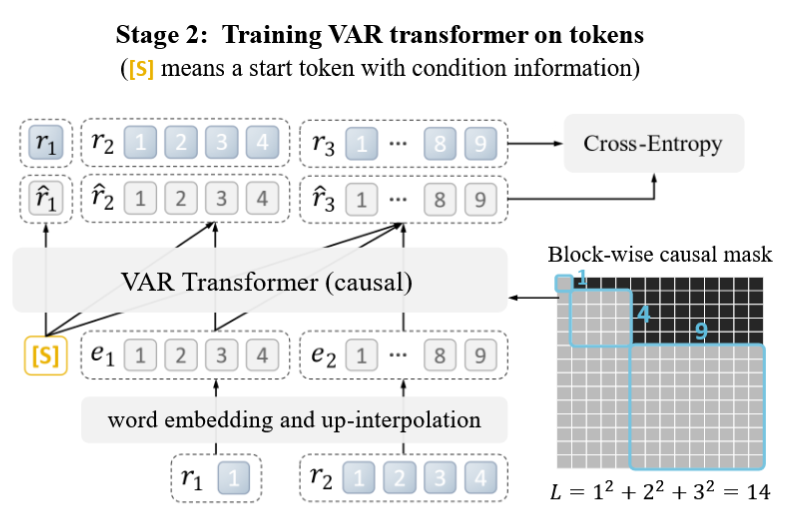
量化:采用了VQGAN中的结构,但修改了其中的多尺度量化层,使用了同样的词本:

重建的时候也用了类似VQGAN的结构:

为了解决上采样的信息损失问题,额外使用了K个卷积层
其复杂度为:O(n4)
假设:
- h=w=n为VQVAE获取的最大的特征图的分辨率(实际为原图分辨率)
- •生成的不同分辨率的图像的宽和高为a(K−1)=n,其中α为缩放系数
最终需要计算自回归的token为(r1,r2,…,rk),一共需要计算k次,由于分辨率依次递增,每次的计算量不同:
i=1∑kni2=i=1∑ka2⋅(k−1)=a2−1a2k−1
最终加和得到:
k=1∑loga(n)+1(a2−1a2k−1)2=(a2−1)3(a2+1)loga(a4−1)logn+(a8n4−2a6n2−2a4(n2−1)+2a2−1)loga∼O(n4)
实现细节
量化器:词本所有尺度为V=4096,量化器在OpenImages上进行训练,下采样率为16×
Transformer:
decoder-only的transformer
使用adaptive normalization(AdaLN)
对于特定类的合成,使用了class embedding作为初始token和AdaLN的条件
在attention归一化query和key可以稳定训练,使用了类relu的归一化:
w=64d,h=d,dr=0.1⋅d/24
其中,w是宽度,h是head的数量,dr是drop比率
由此,总参数量为:
N(d)=self-attention d⋅4w2+feed-forward d⋅8w2+adaptive layernorm d⋅6w2=18dw2=73728d3
超参数:
lr=10−4 per 256 batch,batch=256,AdamW(β1=0.9,β2=0.95,decay=0.05),batch=768~1024,epoch=200~350
实验
对比试验
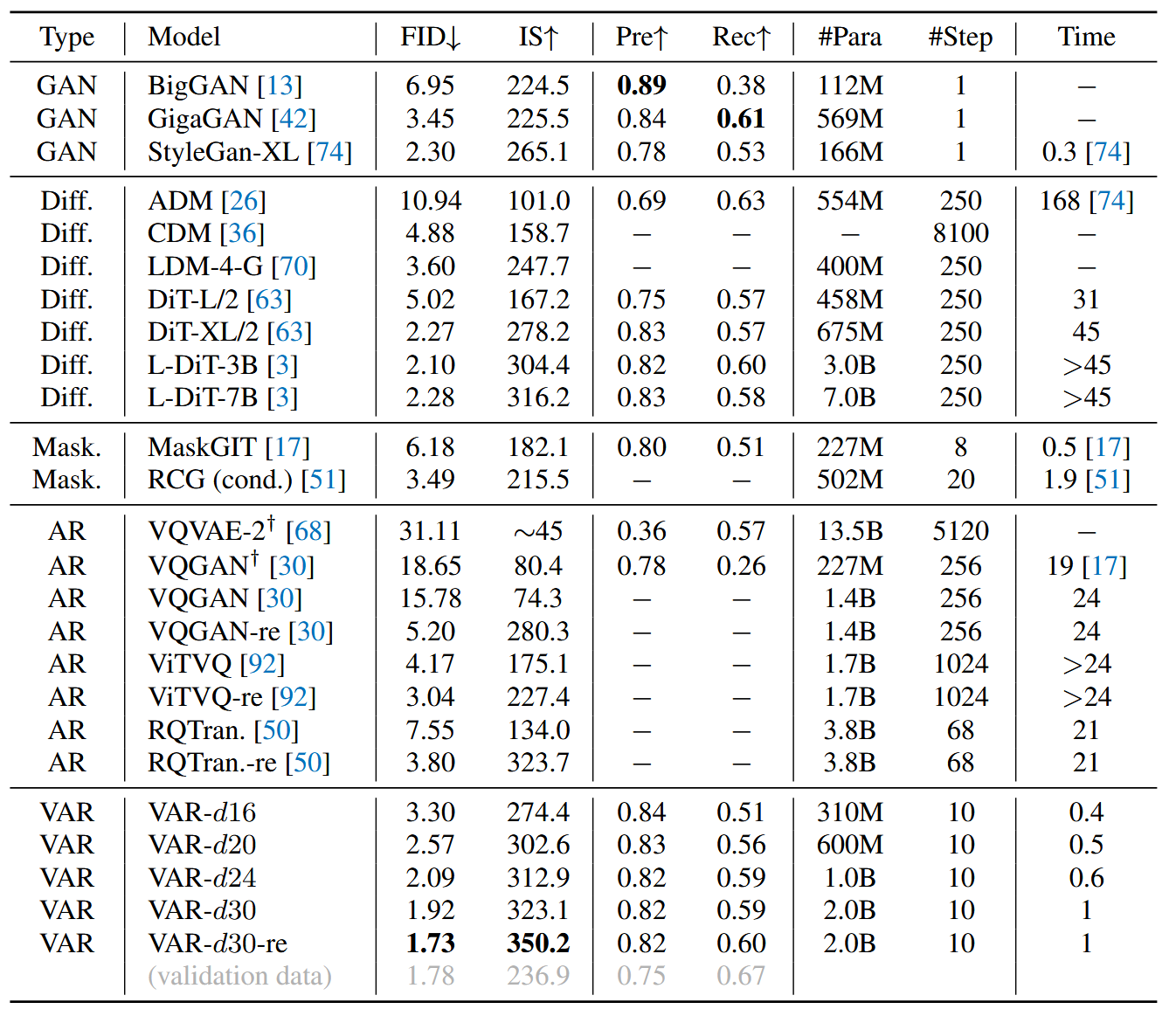
对于256×256,带有类别的生成
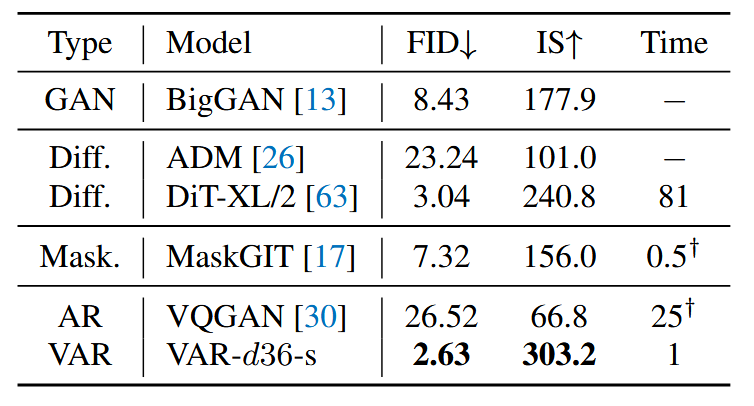
对于512×512的图像:
scaling能力
之前的研究认为扩展AR模型会导致测试损失有一个可预期的下降:
L=(β⋅X)α
其中,X可以任意为参数量N,训练token T,优化训练计算量Cmin,指数上标α表明power-law的平滑性,L代表被不可削减的损失L∞归一化的可削减损失
log(L)=αlog(X)+αlogβ
测试了18M到2B的模型,包含1.28M图像或者870B的token
总结
方法优势:
可能的劣势:
