[论文笔记] DINOv3
信息
Title: DINOv3
Author: Oriane Siméoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien Mairal, Hervé Jégou, Patrick Labatut, Piotr Bojanowski
Publish: arxiv
Origanization: meta
Year: 2025
Code: https://github.com/facebookresearch/dinov3
Dataset: LVD-1689M, SAT-493M
Keyword: 预训练,对比学习,自监督
背景
自监督的好处:
- 无需标注,可以使用近乎无限的数据
- 对分布偏移,提供全局和局部的特征,生成促进物理场景理解的丰富特征
- 无需人工干预,很适合用日益增长的网络数据长期学习
在视觉自监督中,优化方向有:
- 基于重绘的方法:除了像素空间,可学习的的隐层空间预测(JEPA)
- 对比学习:主要从对比目标,信息论,自聚类策略
但仍有以下问题:
- 模型不稳定和崩塌
- 尚不清楚如何从未标记的数据中找出有用的数据
- 使用cosine学习率的前提是知道一个优化边界作为先验
- 在早期学习后,性能反而会下降
在比ViT-Large更大的模型上跑更长时间的训练会出现
目标从三个方面进行改进:
- 通过scale模型尺寸和训练数据提供一个强大的通用模型
- 提升密集图特征(基于像素),同时提供语义和底层几何特性
底层密集特征可以直接用于像素级任务,例如深度估计
值得注意的是,高层语义理解可能会和底层密集特征质量冲突
现有对比学习在相关方向上的改进:
- 局部SSL损失
- 基于蒸馏和聚类的方法,使用多个encoder在不同层级的任务上训练
- 聚焦于事后的局部特征提升
- 模型规模,使用7B训练,其它都是蒸馏
贡献:
- 数据scale方法
- 通过定义ViT的变种(使用现代的axial RoPE,正则化。。。),常数超参数策略
- 使用了带有Gram anchoring训练阶段的pipeline,清楚特征图噪音,生成好的相似图,提升参数化和非参数化密集任务
- 将7B模型的能力迁移到一系列模型上
方法
从大模型的涌现现象得到灵感
数据准备
数据的scale不仅在于数量,也在于质量(多样性,平衡,有用。。。)
DINOv2的数据量只有142M,Web-DINO的数据量在

数据收集
在Instagram上的公开发表获取web图像,经过平台的过滤,有17B数据,创建三个数据部分:
- 使用[基于多层级的K紧邻的自动curation方法](Automatic Data Curation for Self-Supervised Learning: A Clustering-Based Approach),使用DINOv2作为图像编码器,使用5层聚类(200M, 8M, 800K, 100K, 25K),并使用平衡采样策略,得到1689M(LVD-1689M数据集),创造一个包含所有网络图像的数据集
- 使用基于检索的系统,从数据池中选取与给定数据集相似的图像,创建一个与下游任务有关的数据集
- 使用ImageNet-1K,ImageNet-22K,Mapillary Street-level Sequences,通过DINOv2的方法优化最终性能
数据消融

自监督大规模预训练
最近自监督发现scale up尽管在总体上表现良好,但在密集预测上性能差
学习目标
使用了多种全局和局部自监督目标的结合:
- 图像级对比损失
- patch级重建损失
两点改进:
两个损失中都用SwAV中的Sinkhorn-Knopp方法进行centering
由于教师-学生网络,如果教师模型一直输出一个最大分布(所有都是一类),就会使得模型训练崩塌,所以要将教师模型特征进行中心化,使其分布平衡
同时在局部和全局的backbone输出后增加了一个专用的layer norm,稳定了ImageNet KNN分类的准确率,并提升了密集任务的性能
使用一个Koleo正则化损失来让一个batch中的特征分布均匀(在一个batch的16个样本上应用)
基于近邻距离,鼓励更大的近邻距离
总体为:
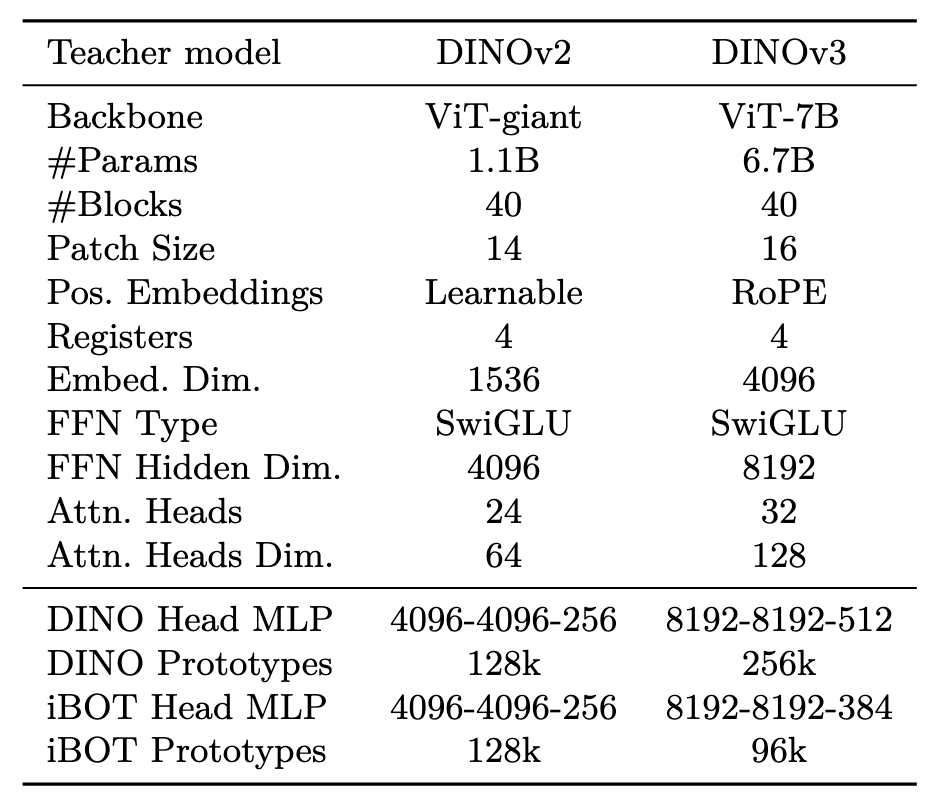
架构更新
增加到7B参数,使用了变种的RoPE,原始的RoPE在[-1, 1]的内分配,为了使模型适用分辨率,缩放,纵横比,使用了RoPE-box变换,在[-s, s]的区间内进行分配,其中,随机选择
RoPE:
假定query和key之间的内积操作可以使用g表示:
那么相对位置编码就是要找到:
可以利用响亮的几何关系(或者说e指数相乘=指数相加)得到如下关系:
而可以使用欧拉公式分解,写为:
优化
由于数据规模和训练数据复杂度,很难估计一个先验,由此很难估计一个正确的优化边界,作者使用了一个常数学习率,权重衰减,教师模型EMA动量,由此,可以:
- 只要下游任务有优化,就可以一直训练
- 减少超参数
同时,对学习率和教师模型温度系数使用了线性warmup,使用AdamW,batch为4096(256GPU),使用multi-crop策略(每张图片2个全局的crop和局部crop,每个crop为256(全局)/112(局部)大小的正方形)
Gram Anchoring
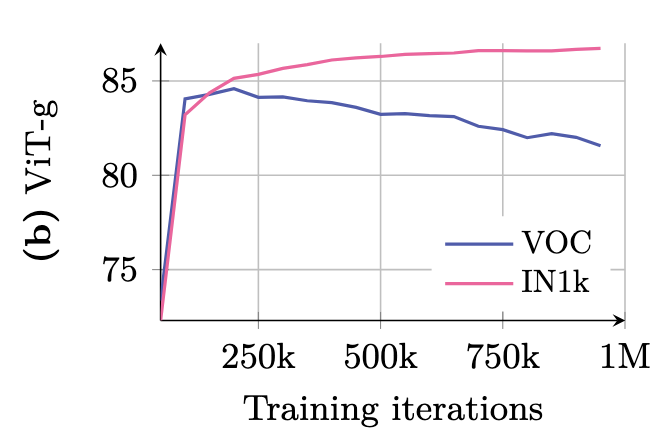
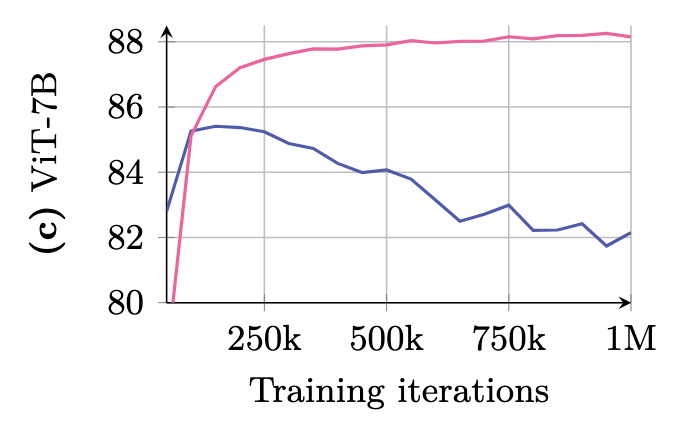
可以看到,在以往的网络中,由于patch级的不一致性,像素级任务的性能会随着训练迭代而衰减
patch级一致性损失
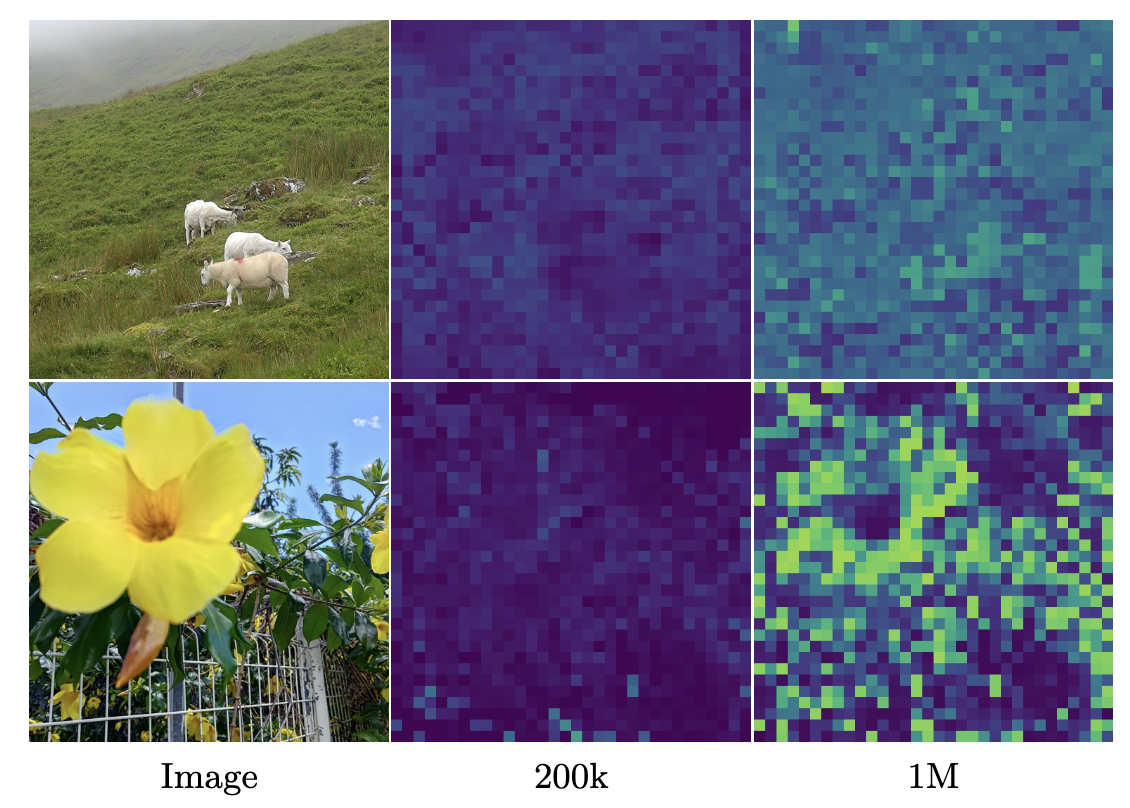
对不同阶段patch和参考patch(红色patch)的余弦相似度进行了可视化,可以看到,在600k之后,出现了许多不相关的patch
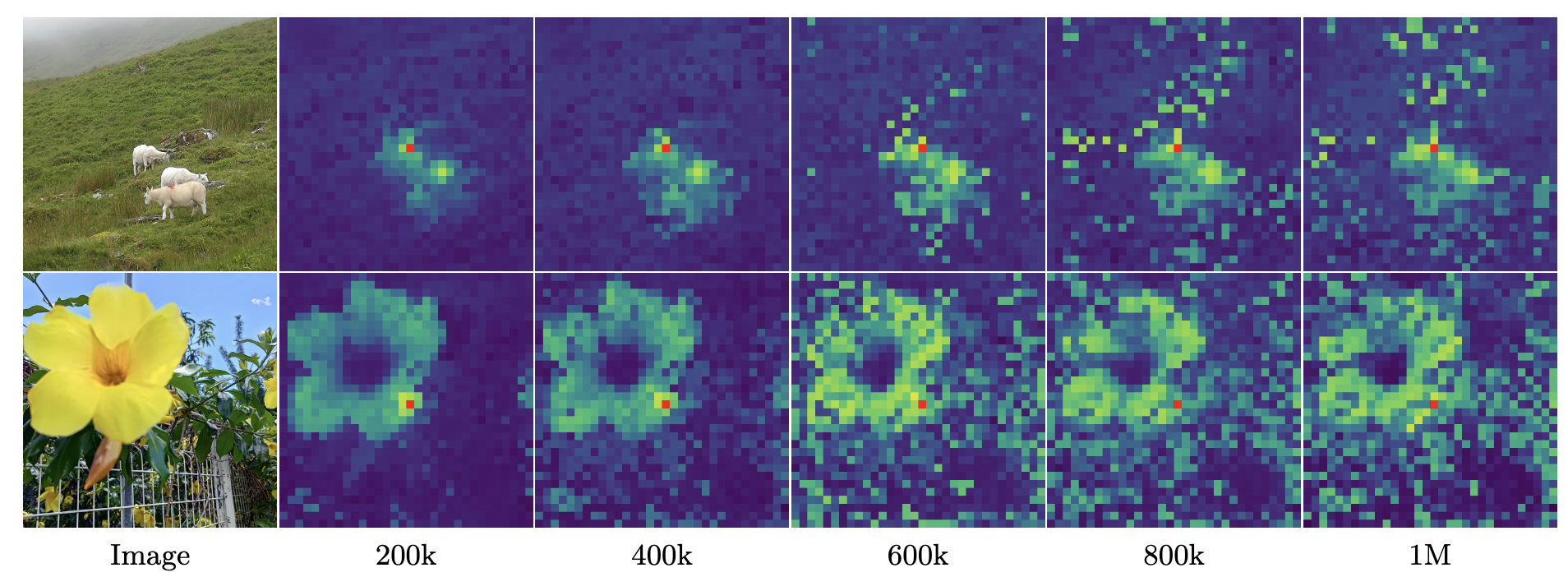
但是,CLS token和各个patch的相似度却在增加:
目标函数
可以从之前的实验看出,学习较强的判别行特征和保持局部一致性一定程度上不相互依赖
可能会相互冲突?
尽管iBOT损失一定程度上增强了对于局部的学习,但是全局损失主导了整个训练过程
由此,在不影响特征本身的情况下,可以强制要求patch级的一致性来解决
通过将学生模型的格拉姆矩阵推向之前的模型(称为格拉姆教师)来实现,选取一个早期iter的教师模型作为格拉姆教师
格拉姆矩阵:两两向量的内积,反应各个向量间的关系
假设有P个patch的图像,网络维度为d,将网络的L2归一化后的局部特征表示为,定义Gram损失为:
只在全局crop上计算这个损失,并且只在1M iter之后计算,但这个损失仍能修复局部特征,同时,格拉姆教师模型在每10k iter更新一次
如何只在全局crop上计算?
由此,最终损失为:
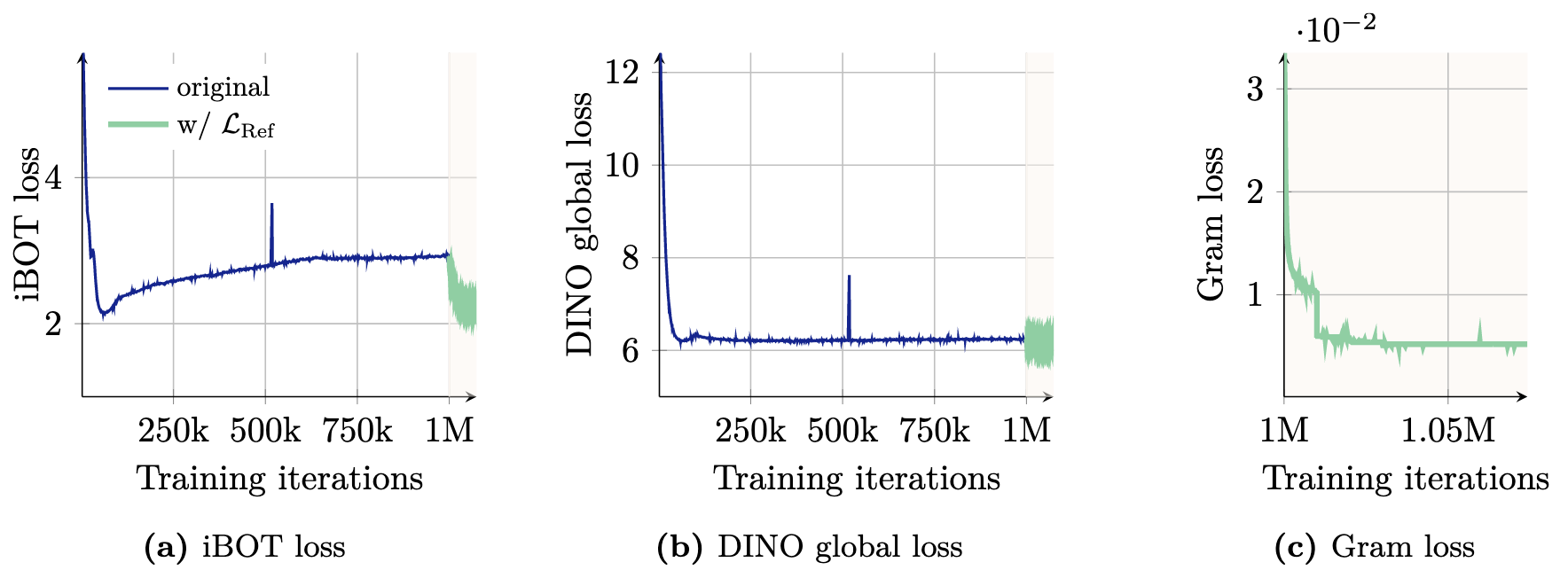
从结果中可以看出,应用格拉姆损失之后,会影响iBOT的损失,但对DINO损失影响不大
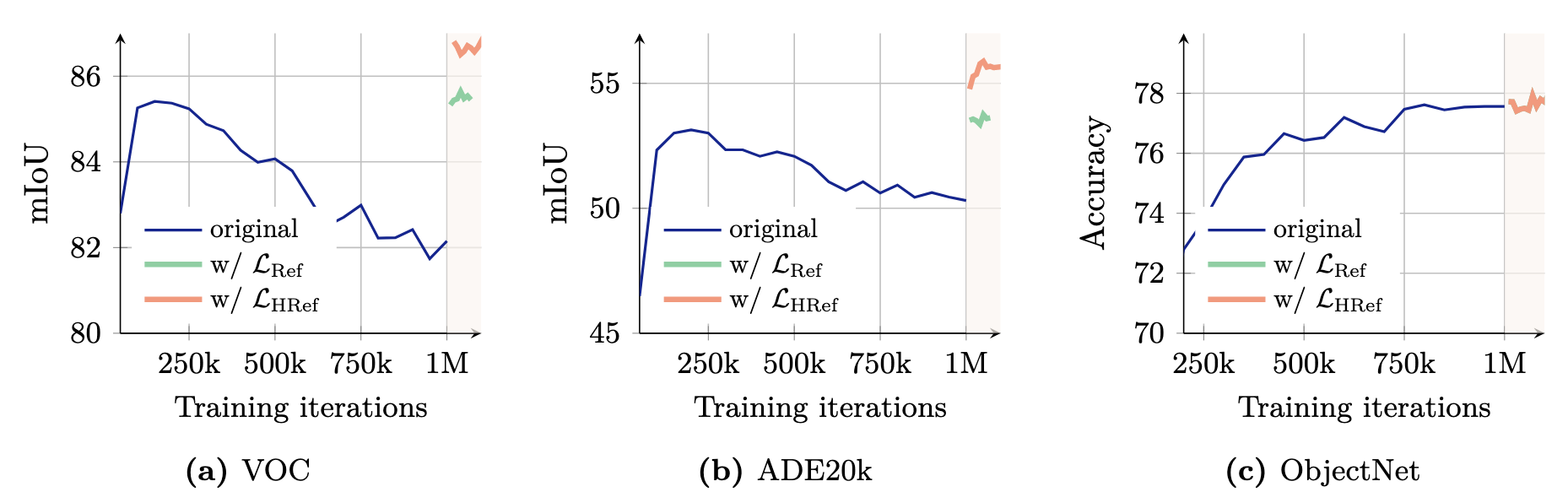
在下游的密集任务上,性能几乎立刻有了提升:
高分辨率特征
最近研究发现对patch特征做一个加权平均可以提升局部特征(平滑外围patch并增强patch级的一致性),另一方面,使用高分辨率图像可以生成更好和有更多细节的特征图
由此,对于格拉姆教师网络,使用两倍的分辨率输入图像,然后对于输出特征做两倍下采样,并利用双线性插值来获得更平滑的特征与学生网络的输出匹配
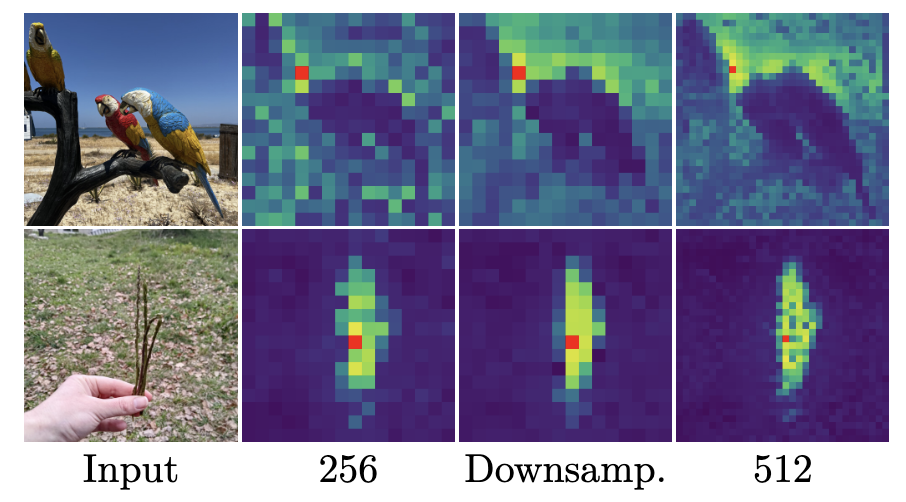
DINOv3可以处理任何分辨率图像
用下采样后的特征取代之前损失中的,形成新的优化目标,由此可以让平滑的高分辨率特征蒸馏到学生网络中

后训练
分辨率缩放
模型在256p分辨率上训练,patch为16,通过一个高分辨率适应阶段来拓展,使用混合分辨率,通过在batch中采样不同大小的全局{512, 768}和局部crop{112, 168, 224, 336}训练额外的10k iter
与分辨率,patch14的DINOv2特征长度一致
有趣的是,最终模型能处理的最高分辨率超过了768,甚至可以达到4k
模型蒸馏
通过7B模型蒸馏得到ViT的变体,蒸馏方法使用与第一阶段训练相同的目标,使用7B模型(冻结)作为教师而非EMA,由于没有patch级一致性问题,也没有应用Gram anchoring
在ViT边体重,增加了有额外参数的ViT-S+(29M)和ViT-H+(0.8B)
多学生蒸馏
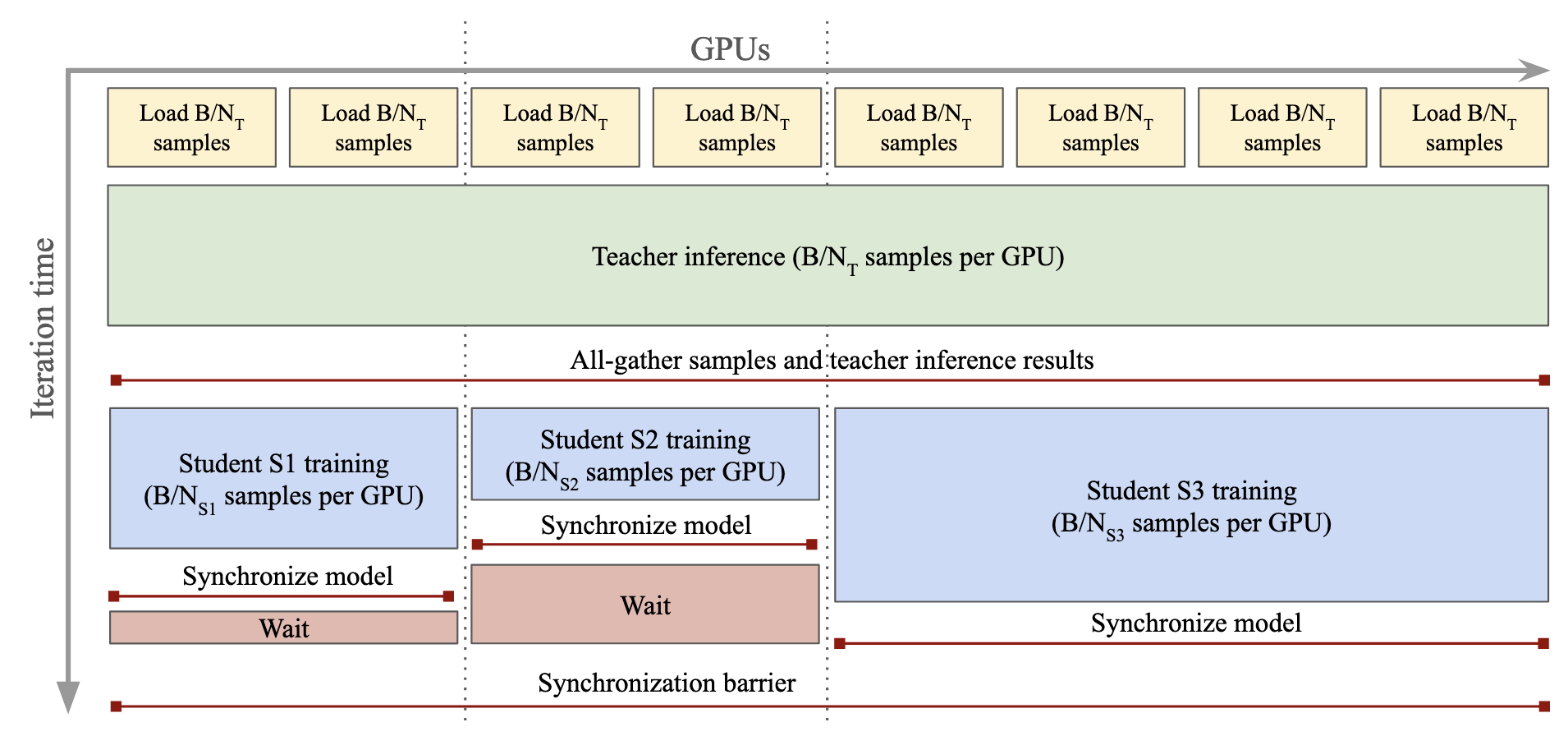
与文本对齐
CLIP的对齐只针对于全局表征
LiT: Zero-Shot Transfer with Locked-image text Tuning展现了预训练的视觉backbone可以实现有效的图像-文本对齐
文中使用了DINOv2 meet text中的方法,大体是保持视觉encoder固定,训练一个文本模型来对齐图像的描述,为了一些灵活性,在视觉编码器后增加了两个transformer层,并且,使用平均池化的patch embedding和CLS token的拼接结果匹配文本embedding,可以同时实现全局和局部对齐
实验
将DINOv3冻结
密集特征
定性分析
使用PCA将密集特征降维到3维,并映射到RGB

密集Linear Probing
应用到语义分割和弹幕深度估计(都使用1024的patch长度,即使用patch 14,使用patch 16)
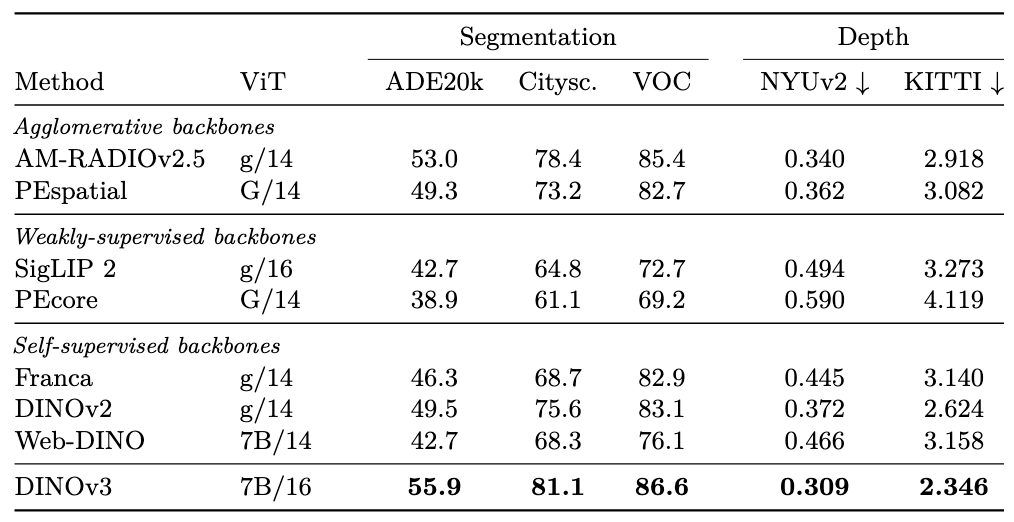
3D关系估计
3D世界关系是基础模型重要的特征,测评了多视角一致性(一个物体不同视角的patch特征是否相似),区分几何(相同物体)和语义(同类不同物体)估计
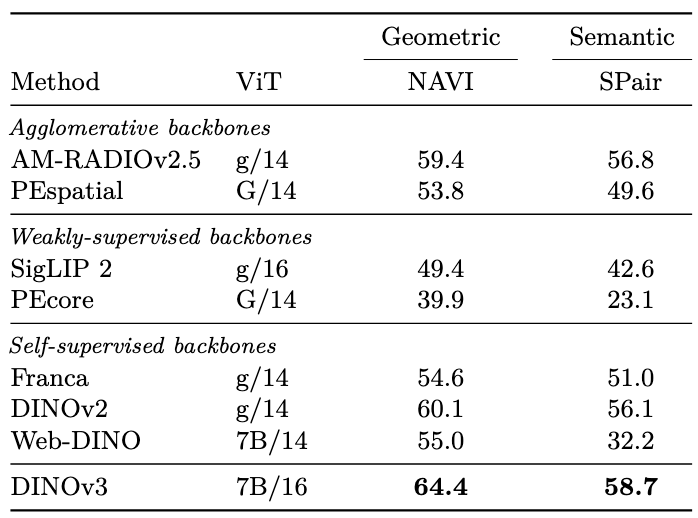
无监督物体发现
良好的自监督特征可以帮助在没有任何标注的情况下发现物体实例,通过使用非参数化基于图的TokenCut算法进行衡量
DINOv2尽管有很强的密集特征,但在物体发现上性能落后,可能由于密集特征中的artifacts特征
视频分割追踪
视觉特征的一个重要能力是时间一致性,在S(420/480),M(840/960),L(1260/1140)分辨率上进行了实验
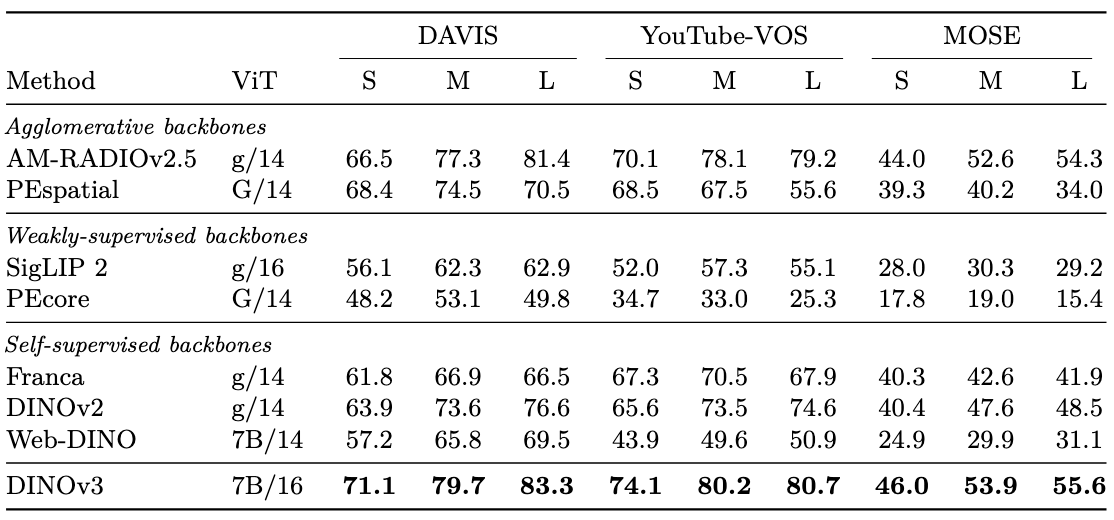
尽管没有在视频上训练,还是取得了最好的性能
视频分类
进行高层视频语义分类,使用attentive probe(4层transformer分类器)
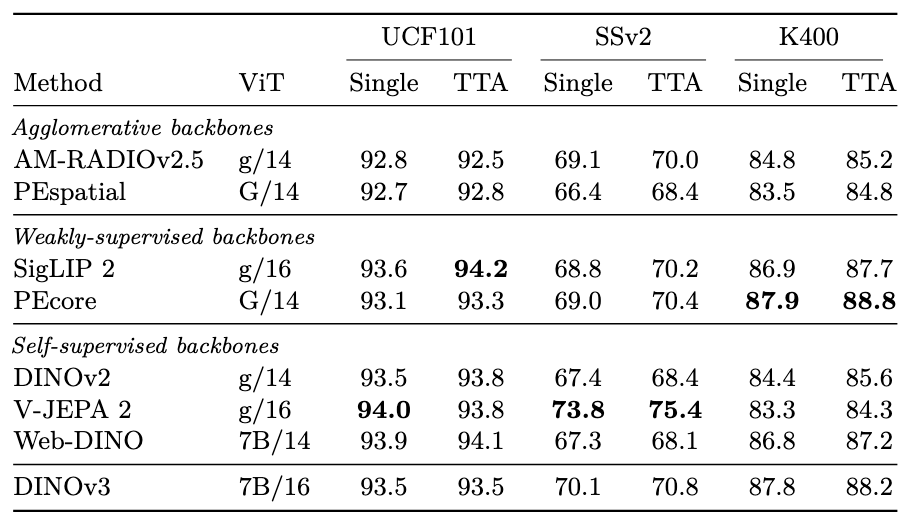
全局图像描述
图像分类
在DINOv3的CLS token上训练一个线性分类器,带*的评估方法不同
对于ImageNet家族:
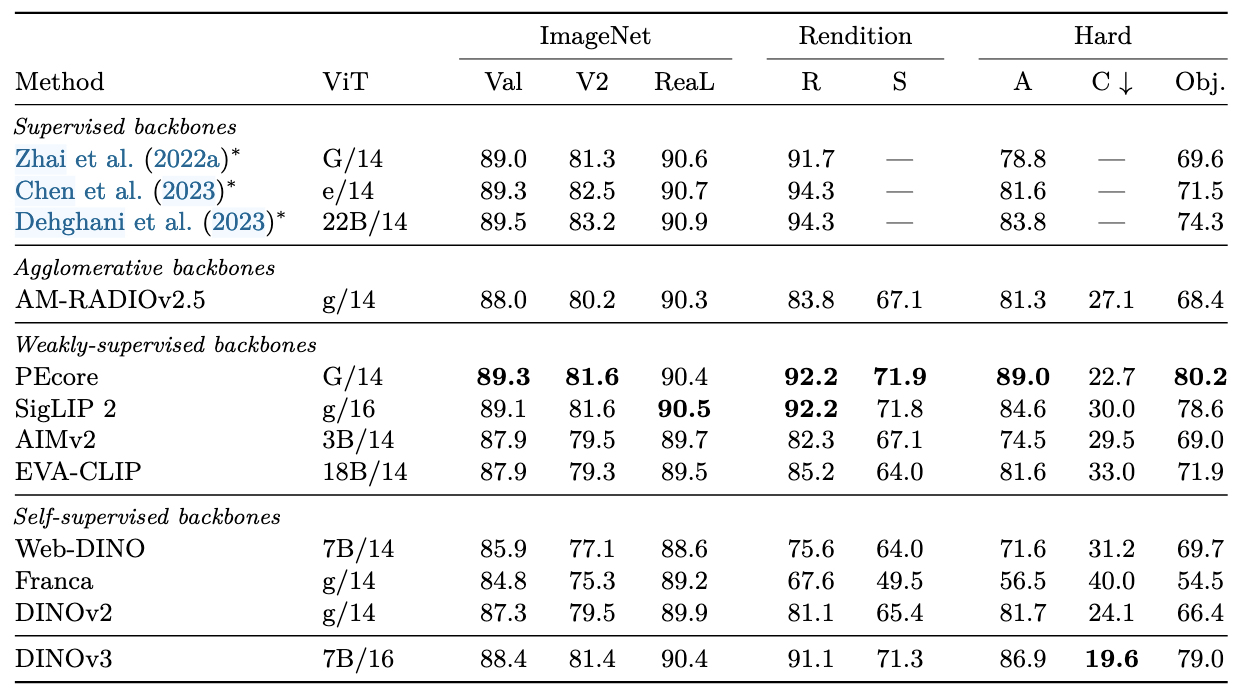
对于细粒度分类:
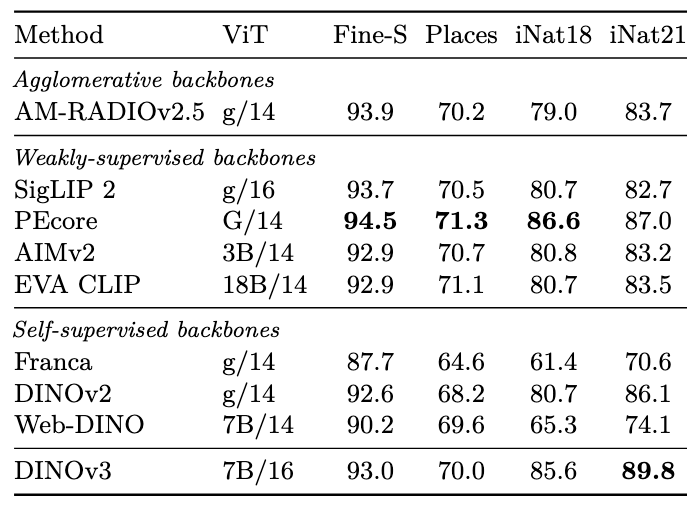
实例识别
使用一个非参数化搜索方法,使用CLS token,对数据库中的图像和给定图像做余弦相似度排序

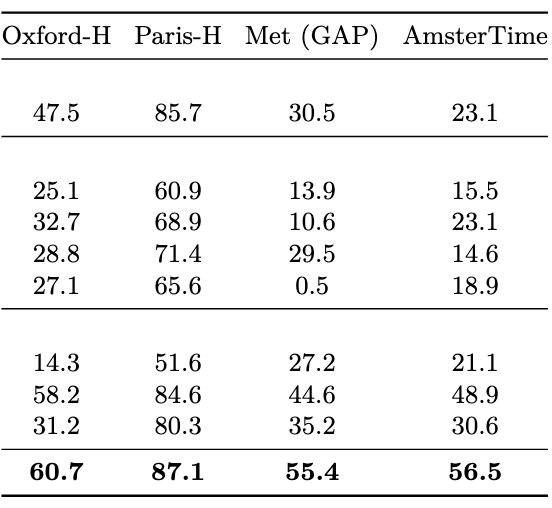
复杂视觉系统
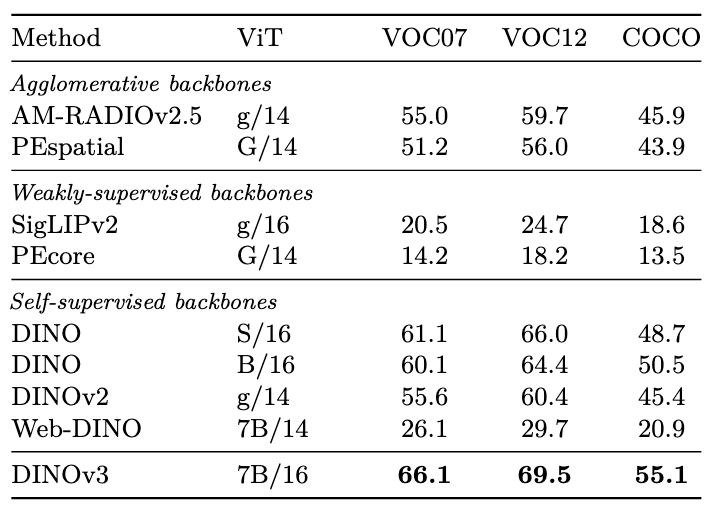
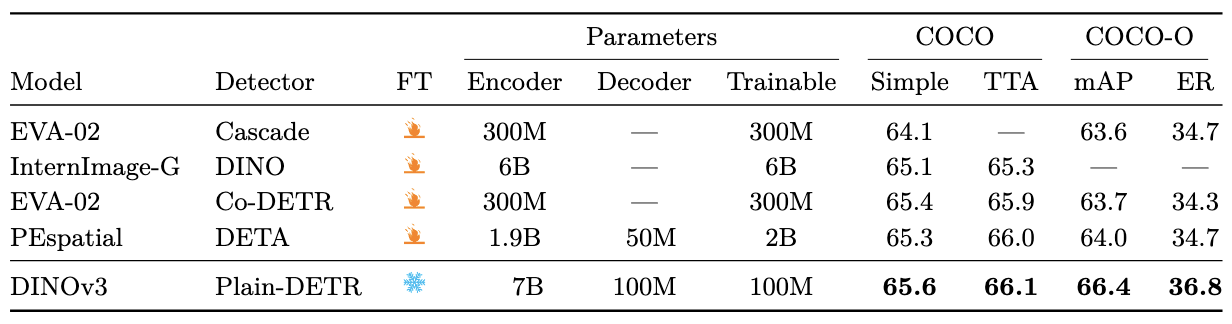
目标检测
使用Plain-DETR(但不将trasformer encoder融入backbone中),冻结backbone
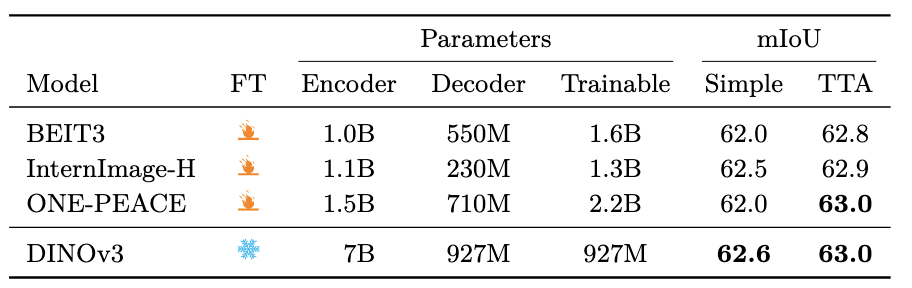
语义分割
使用ViT-Adapter和Mask2Former,但是,ViT-Adapter衣橱了injector部分,并且embedding dimension提升到了2048,与DINOv3的4096维度匹配,输入分辨率为896
单目深度估计
使用Depth Anything V2,其使用了大量gt深度标注来合成图像
这种合成-真实的gap,也是SAM无法处理的
但把分辨率从提升到了DINOv3的高分辨率,同时,也scale了DPT头的大小

视觉几何定位(3D理解)
使用VGGT,替换了其中的DINOv2(使用ViT-L),输入分辨率为到
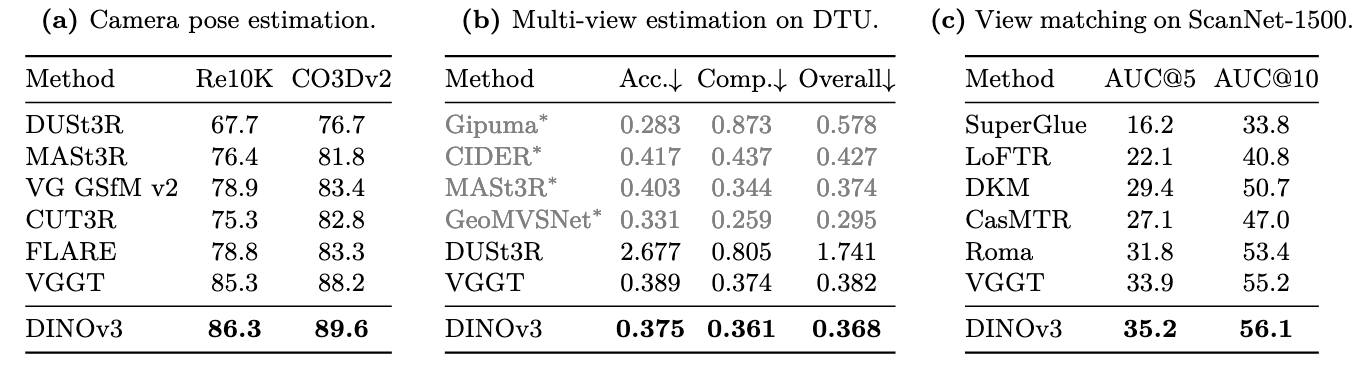
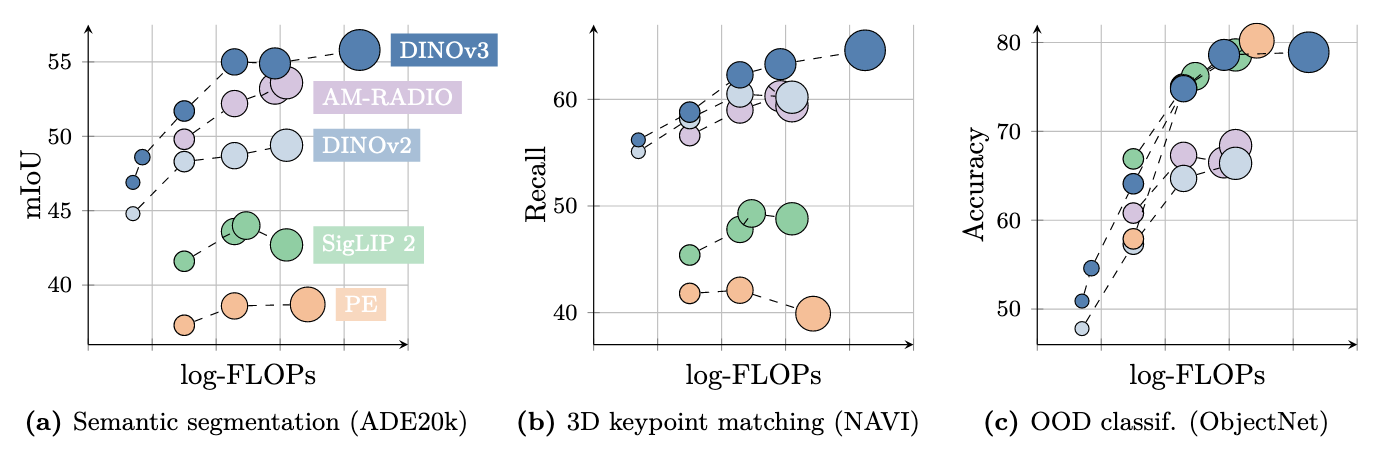
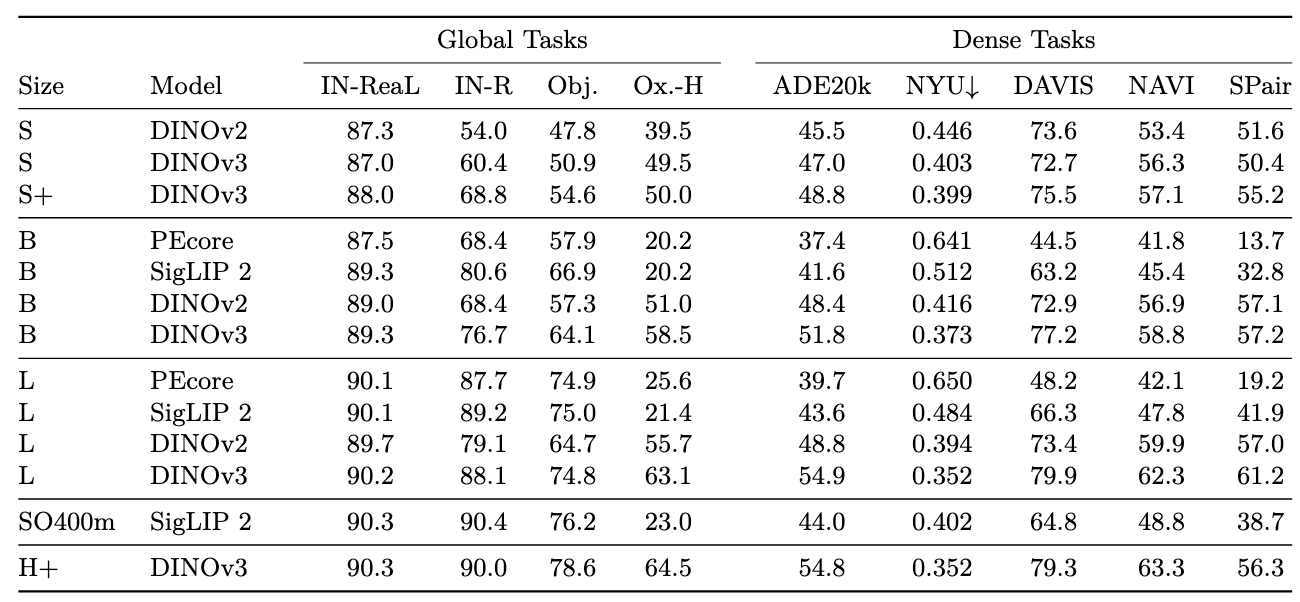
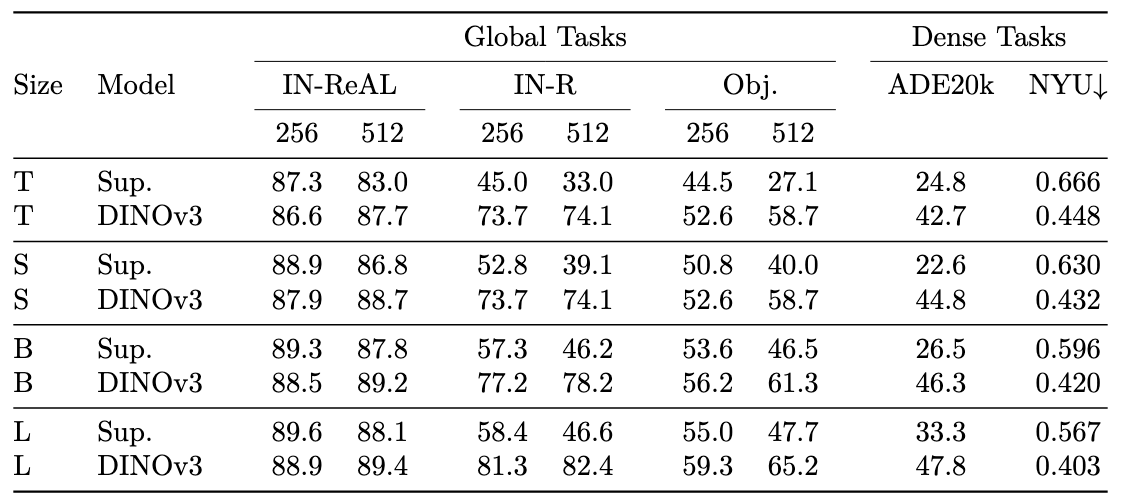
整个DINOv3家族性能
蒸馏了ViT和ConvNext的变体
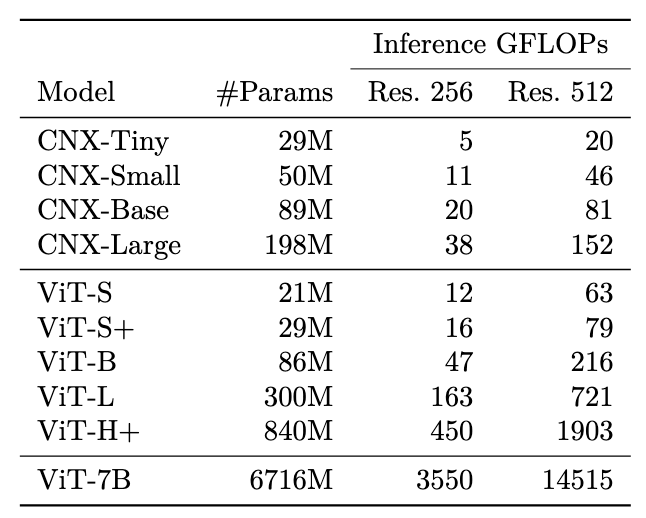
ViT变种
ConvNext变种
ConvNext计算量更小,并且卷积有更好的量化策略
零样本能力
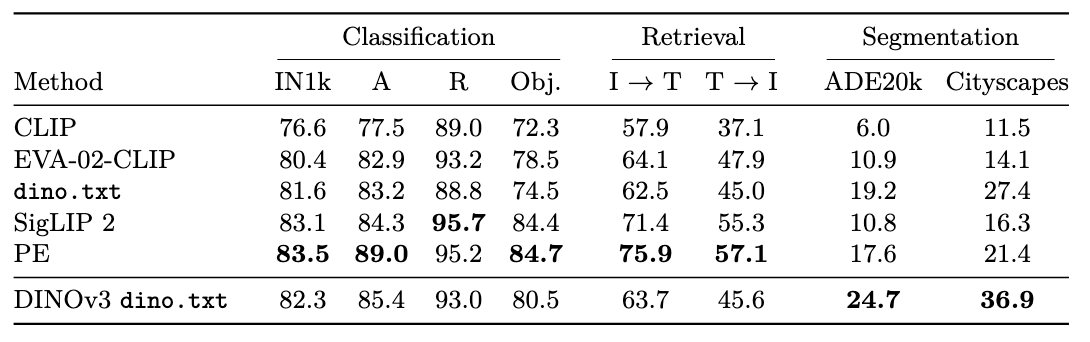
遥感数据
在SAT-493M上进行训练,包含493M 大小,0.6M分辨率,Maxar成像系统(包含Geoeye-1,WorldView-2等卫星)捕获的RGB图像
实验
天空高度估计
使用RGB-LiDAR数据,LiDAR数据作为高度的gt
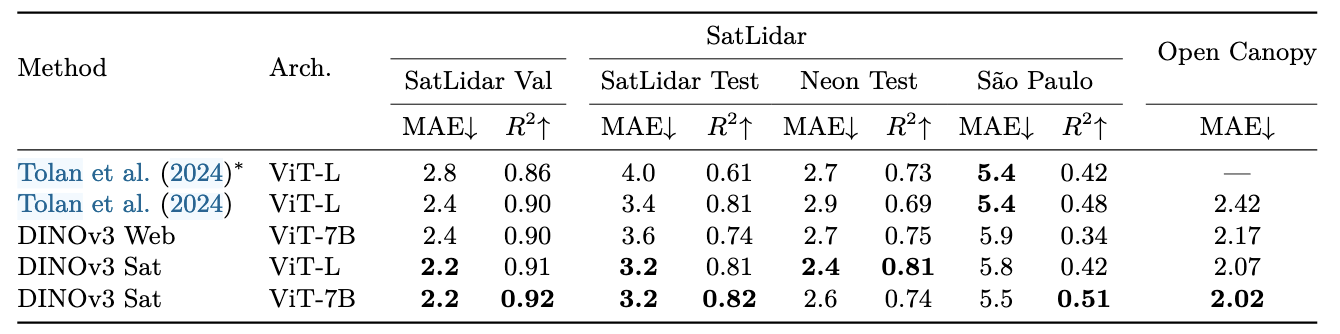
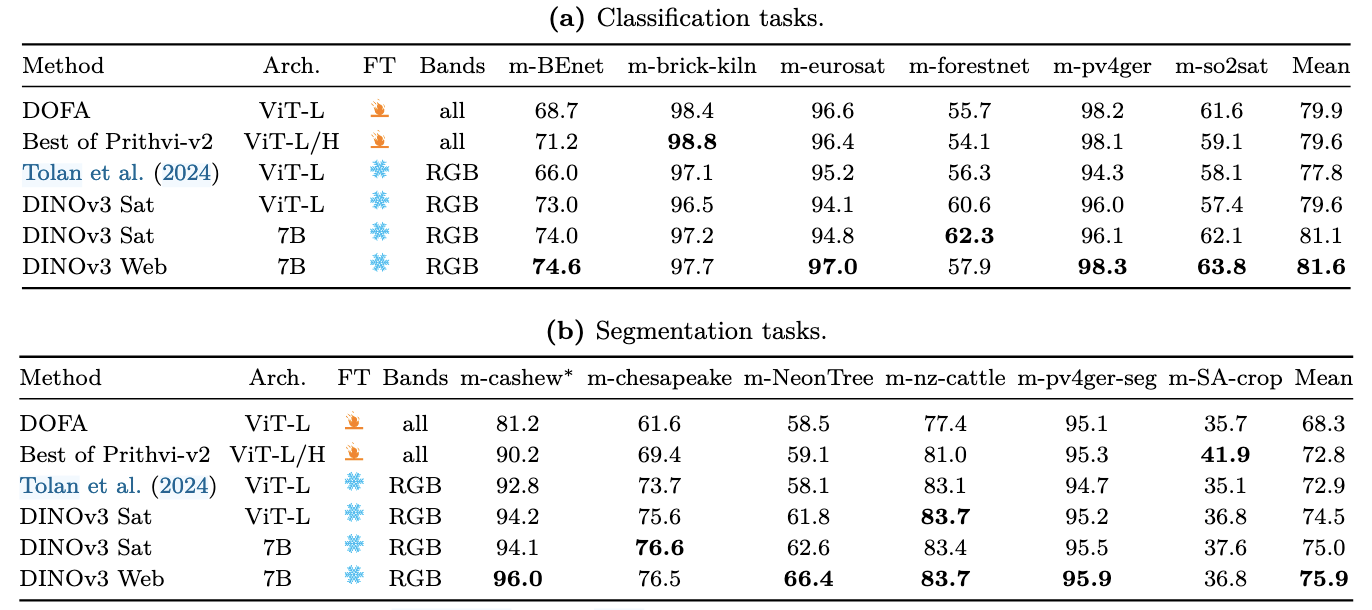
地球观测
很奇怪的是,Web图像还要比卫星图像更好,有几种可能的解释:
- SAT-493受限于成像系统,数据来源,并且只有0.6M分辨率,RGB
- 遥感图像和自然图像的领域差距并没有想象的那么大
总结
本篇文章探究了大规模自监督学习在数据处理,密集特征增强等方面:
数据的scale不仅在于数量,也在于质量(多样性,平衡,噪声。。。)
语义特征和像素特征一定程度上不相互依赖,利用格拉姆矩阵损失提升密集特征
Scale并获得高质量的基础模型
不足:
遥感部分数据收集和结果异常
语义特征和密集特征不能解偶(数据量剧增,但分类,识别等任务提升微小)